🚨 글의 모든 내용은 가천대 WIND [IT특강] 빅데이터 특강을 수강한 후, 정리한 글입니다. 이 글의 목적은 스스로 정리하였지만, 자세한 내용 및 출처는 모두 나영희 강사님께 있음을 다시한번 알려드립니다. 문제가 있을 시, 해당 이미지 및 소스코드는 삭제하겠습니다. 🚨

지난 7월 10일 ~ 14일까지 빅데이터분석실무2급 특강을 수강했다.
필기와 실기 모두 치른 상태이다. 그래서 해당 특강에서 배운 내용을 정리하여보았다.
빅데이터 분석 실무 2급 내용정리
2023년 7월 10일 ~ 2023년 7월 13일

참고로, 문제는 연습문제/퀴즈/실습 위주로 냈습니다!
[Q] Question2. 빅데이터분석실무2급 내 맘대로 정리 (문제)
minsllogg.tistory.com
🌞Intro
빅데이터 분석가에서는 위 3가지 역량이 요구된다. 그 중 컴퓨터 사이언스 능력은 R이나 Python과 같은 분석과 관련된 프로그래밍 사용 능력, 데이터베이스 프로그램 사용 능력을 필요로 한다.
이 특강에서는 R 프로그램을 이용해서 “키워드 추출 텍스트 마이닝” 하는 법을 배웠다.
R 프로그램 특징
- 오픈소스로 개인, 기관, 기업에서 무료로 사용 가능 (상용 제품을 만들 경우엔 라이센스 비용 지불해야 함)
- 다양한 통계 방법을 적용한 데이터 분석 기능
- 2D, 3D 그래픽, 지도, GPS, 동적 그래프 등 다양한 그래프 기능
- 텍스트, CSV, 엑셀, SAS, SPAS, Stada, DB든 다양한 데이터를 읽어오는 기능. 즉, 수정, 삭제, 정렬, 합치기 등의 데이터 핸들링을 위한 기능이 있다.
- 메모리 RAM에서 작동되기 때문에 데이터 처리가 빠르다.
1. R 구성
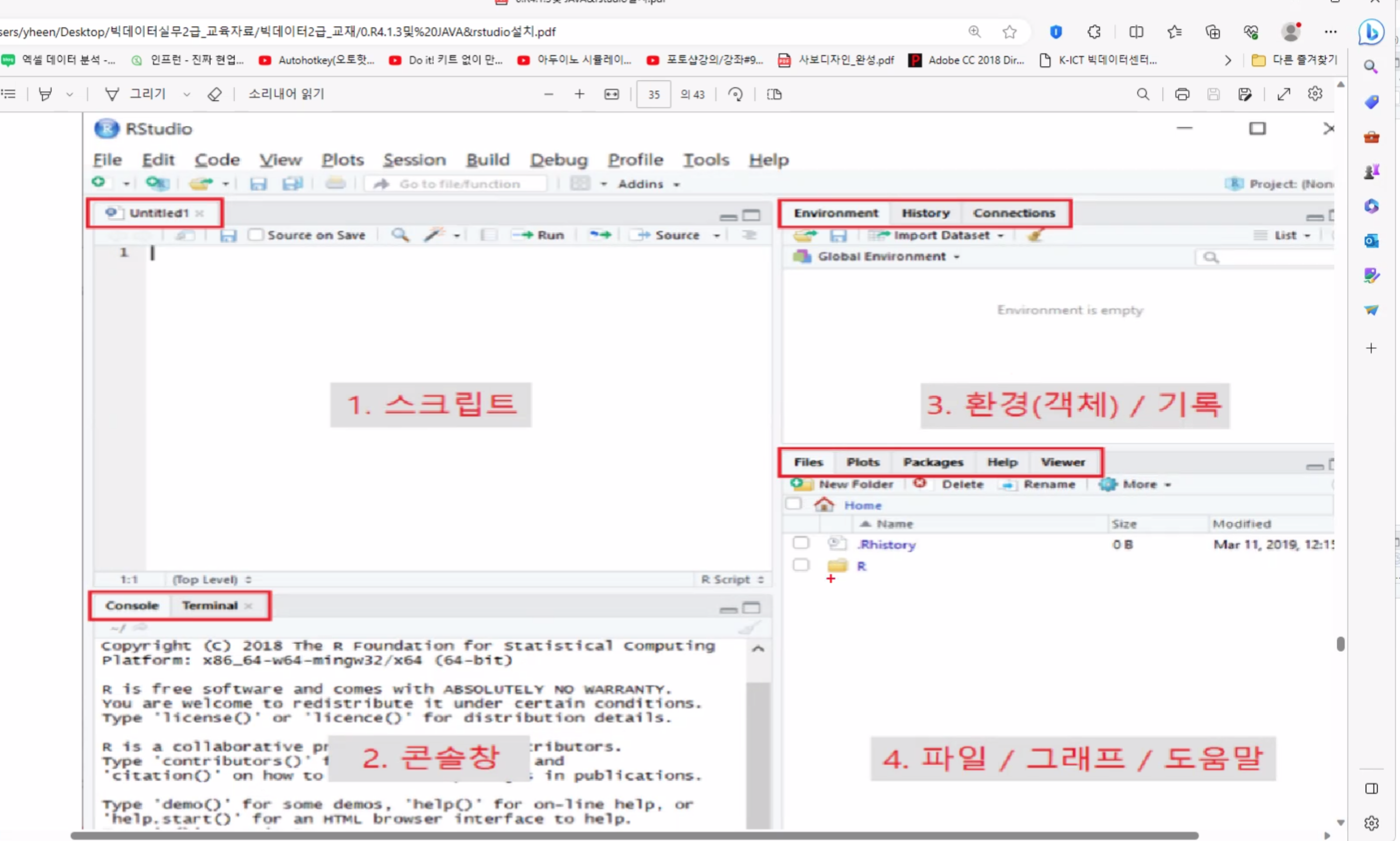
콘솔창 기본 명령어
Enter: 실행Ctrl + R: 스크립트 창에서 실행Ctrl + L: 콘솔 스크린창 지우기
2. R의 기초 사용법
- R studio 프로그램에서 스크립트 이용해서 명령어를 실행하고 저장함
- 대소문자 구별해야 함
기본 기능
- 해시기호(
#): 주석 - 세미콜론(
;): 명령어가 끝났음을 알려주는 기능 (한줄에 하나밖에 없으면 자동으로 끝났음을 인식함) - 여러 적 한번에 실행하기 : 실행할 명령들을 블록으로 선택한 후 Ctrl + R
- 작업 디렉토리 지정
- 작업 디렉토리란? R 사용할 때 필요한 데이터들을 모아두는 장소
- 사용자가 임의의 폴도를 생성한 후 아래 명령어로 지정
setwd(”c:\\temp”)
- 현재 디렉토리 확인 :
getwd() - 설치된 패키지 경로 확인:
.libPaths() - 설치된 패키지 확인 :
installed.packages()
3. 변수와 여러가지 데이터 유형들
(1) 변수
a<-1orb->1: 이러한 형식으로 변수에 대입
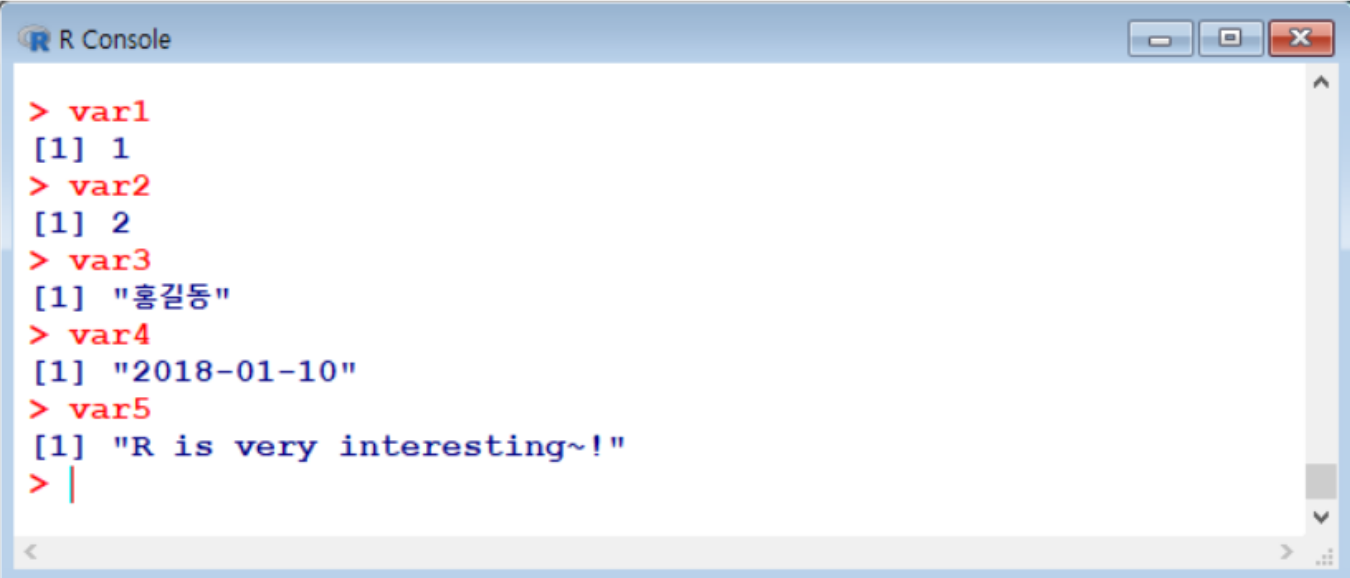
(2) 데이터
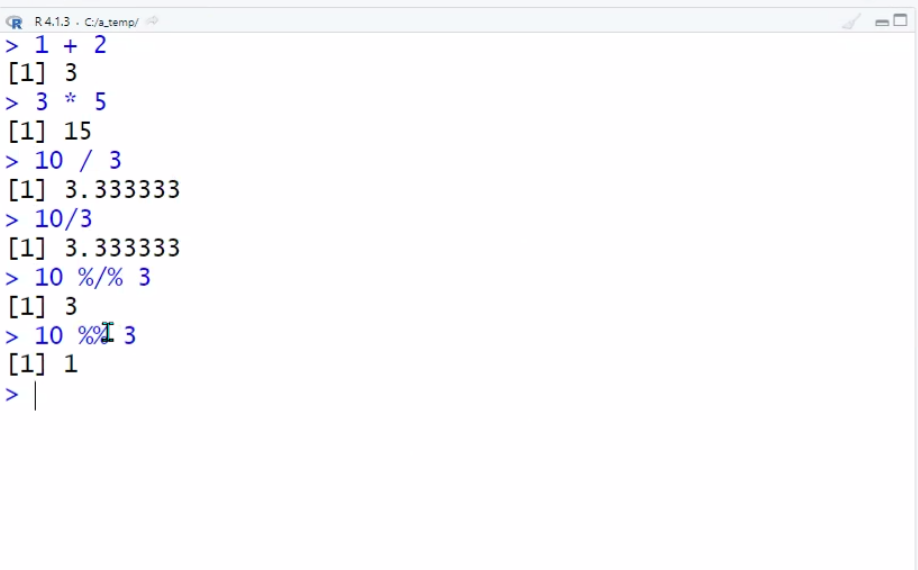
/: 나누기%/%: 몫%%: 나머지<-or=해서 변수에 값 대입print(’변수명’)⇒ 변수 값 출력됨
✔️숫자형 데이터 함수
round(): 반올림trunc(): 소수점 이하 버리기ceiling(): 괄호 안 숫자보다 큰 정수 중 가장 가까운 정수floor(): 괄호 안 숫자보다 작은 정수 중 가장 가까운 정수
> ceiling(4.3) # 4.3보다 큰 정수중 가장 가까운 정수
[1] 5
> floor(4.3) # 4.3보다 작은 정수중 가장 가까운 정수
[1] 4
>
> round(5.33, 0) #소수점 0번째 자리까지 반올림
[1] 5
> round(5.33, 1) #소수점 1번째 자리까지 반올림
[1] 5.3
> round(5.53, 0) #소수점 0번째 자리까지 반올림
[1] 6
> trunc(5.5) # 소수점 이하는 무조건 버리기
[1] 5
> trunc(5.3) # 소수점 이하는 무조건 버리기
[1] 5
>✔️문자형 데이터
→ 쌍따옴표!
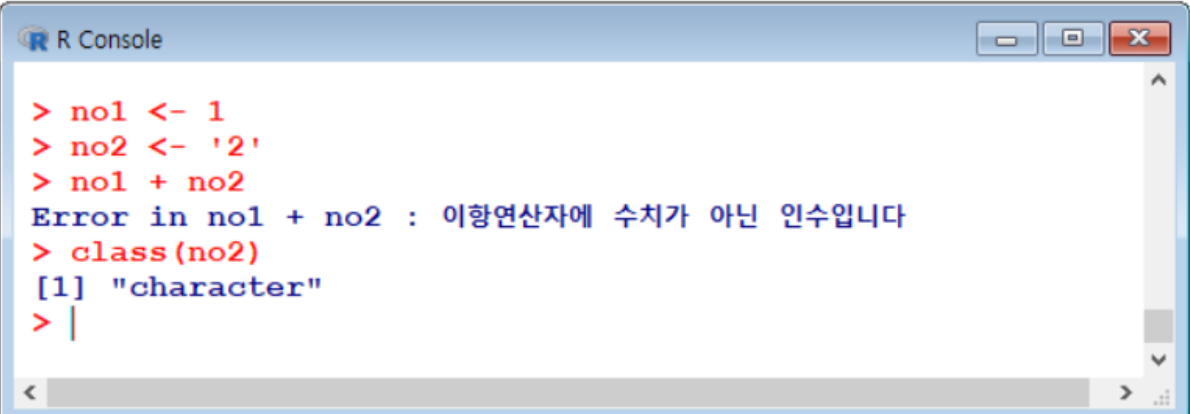
✔️날짜형 데이터
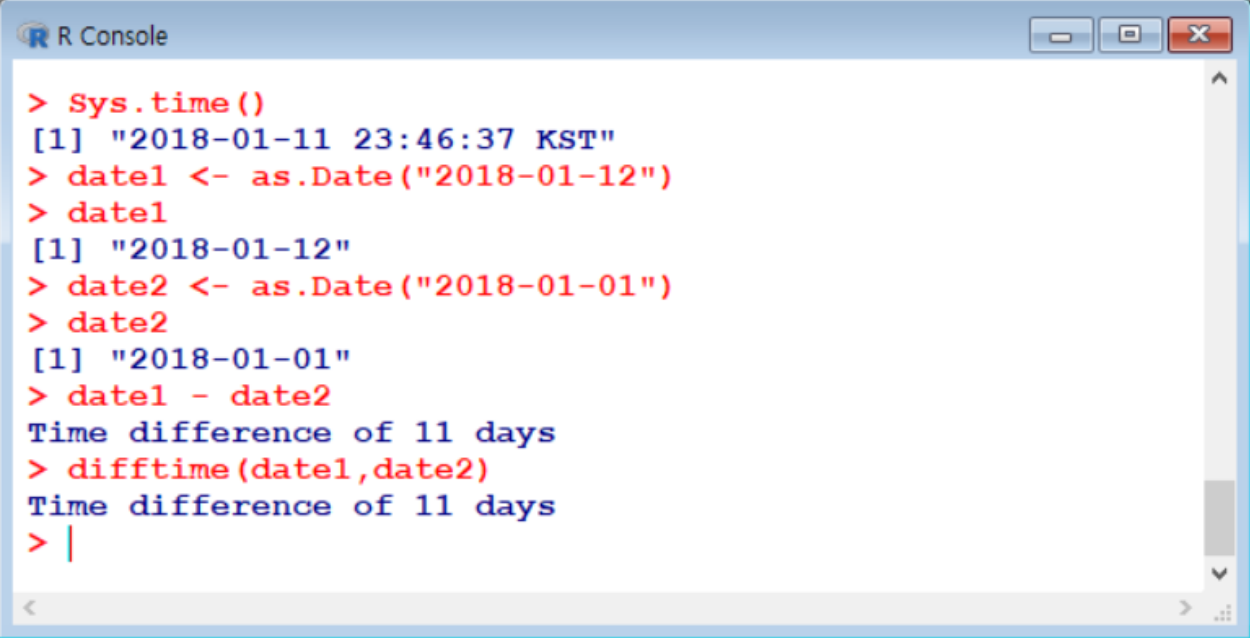
- 현재 날짜 :
Sys.time()(또는POSIXct( ),POSIXlt( )) - 문자열 (예를 들어 31/01/2018) 형태로 되어 있는 날짜를 진짜 날짜로 바꾸어
주는strptime( ) - 두 개의 날짜 사이의 차이를 계산해 주는
difftime( ) - 날짜로 바꾸어주는 함수인
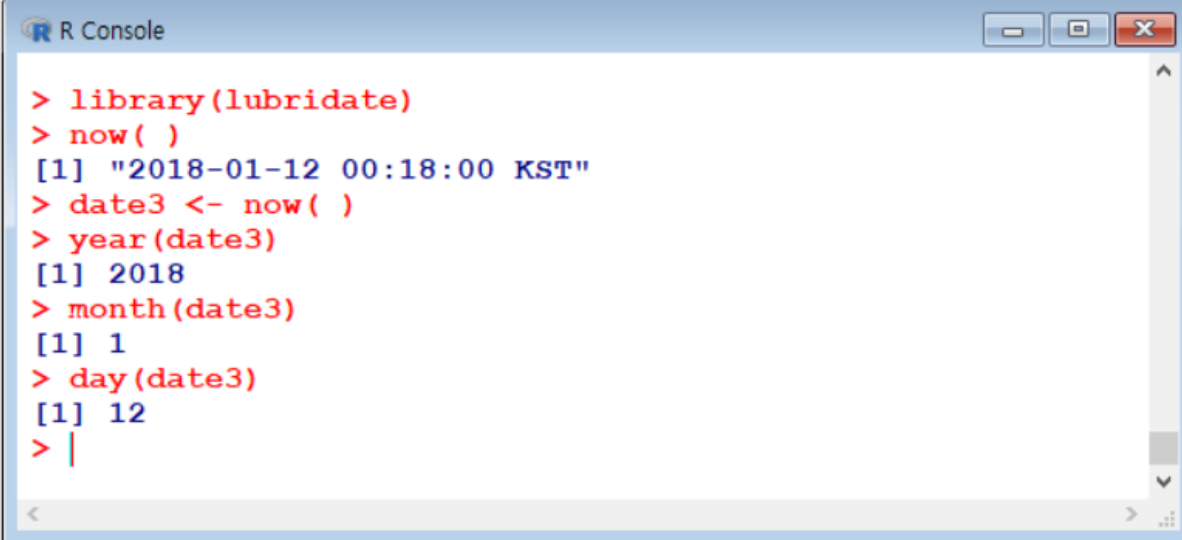
as.Date( )함수 lubridate( )→ 날짜를 조금 더 편하게 사용할 수 있도록 도와주는 패키지 (다음에 더 찾아보기)
NA형, NULL형
NA (Not Applicable, Not available) : 사용할 수 없는 데이터
ex. 숫자가 들어가야 하는 컬럼에 문자형 데이터가 들어온 경우, NA로 표시
- NA 데이터끼리 연산하면 산술연산이든 비교연산이든 결과는 전무 NA로 나옴
NULL : 데이터가 없다.
- NA 와 다르게 NULL 과 연산을 하면 NULL 값을 자동으로 제외시키고 연산
(3) 벡터 Vector
여러 건의 데이터를 한 줄로 쭉 세우고 그 데이터들을 하나의 그릇에 저장하는 형태

- 벡터에 한번에 데이터를 넣고 싶다면 ?
c()이용 c(): 여러 벡터들을 붙여주는 (concatenate) 함수- 주의 : 반드시 모두 같은 데이터 유형만 들어가야 함
> var1 <- c(1,2,3) > var1 [1] 1 2 3 > is.vector(var1) [1] TRUE
벡터 데이터 조회

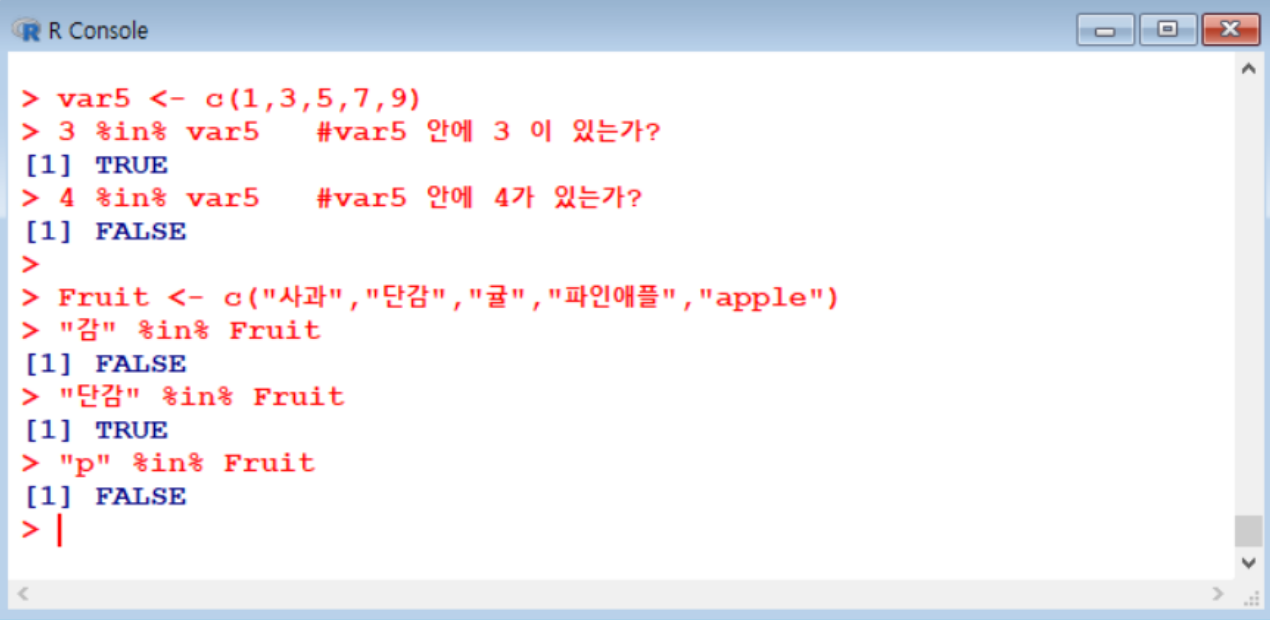
%in%연산자: 특정 데이터가 있는지 없는지를 확인하는 기능
벡터 데이터 연산
> vec1 <- c(1,2,3)
> vec2 <- c(4,5,6)
> vec1 + vec2
[1] 5 7 9
> vec3 <- c(1,2,3,4)
> vec1 + vec3
[1] 2 4 6 5
경고메시지(들):
In vec1 + vec3 : 두 객체의 길이가 서로 배수관계에 있지 않습니다.
> length(vec1)
[1] 3
> length(vec3)
[1] 4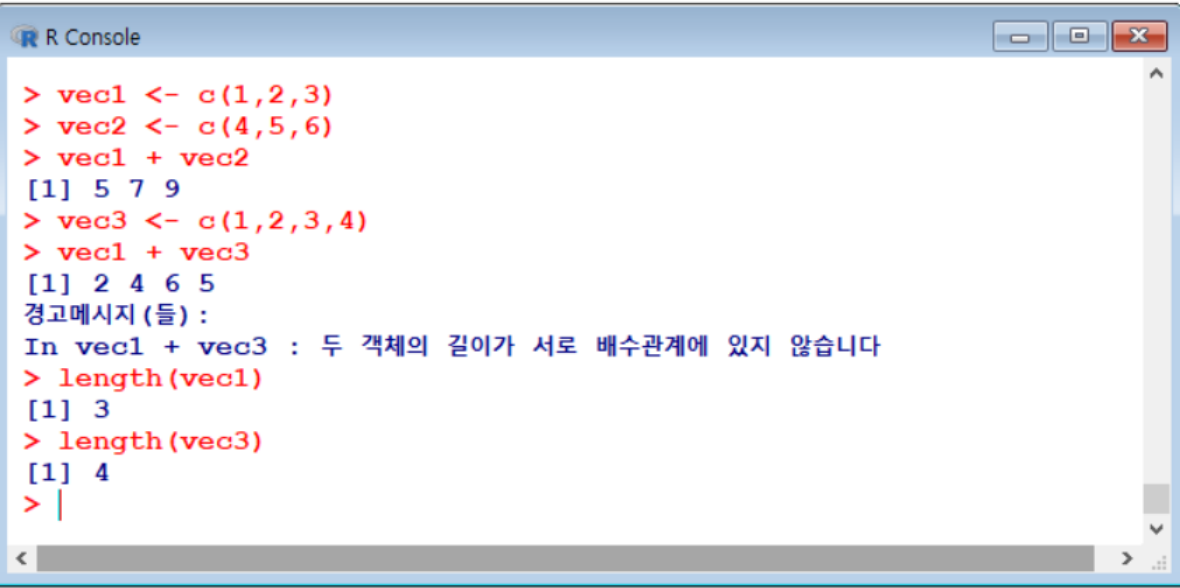
- 산술연산 가능. 단, 벡터의 길이가 같아야 하고, 다를 경우 가운데 부분처럼 에러 발생
length(벡터이름): 벡터의 길이를 확인하는 명령어
> vec1
[1] 1 2 3
> vec2
[1] 4 5 6
> vec3
[1] 1 2 3 4
>
> union(vec1, vec2)
[1] 1 2 3 4 5 6
> setdiff(vec3, vec1)
[1] 4
> intersect(vec2, vec3)
[1] 4
>union(): 여러 벡터의 내용을 합치는 기능setdiff(벡터1,벡터2): 벡터1에 는 있는데 벡터2 에는 없는 것을 찾는 기능intersect(벡터1,벡터2): 교집합 찾는 기능
💯Vector 연습문제
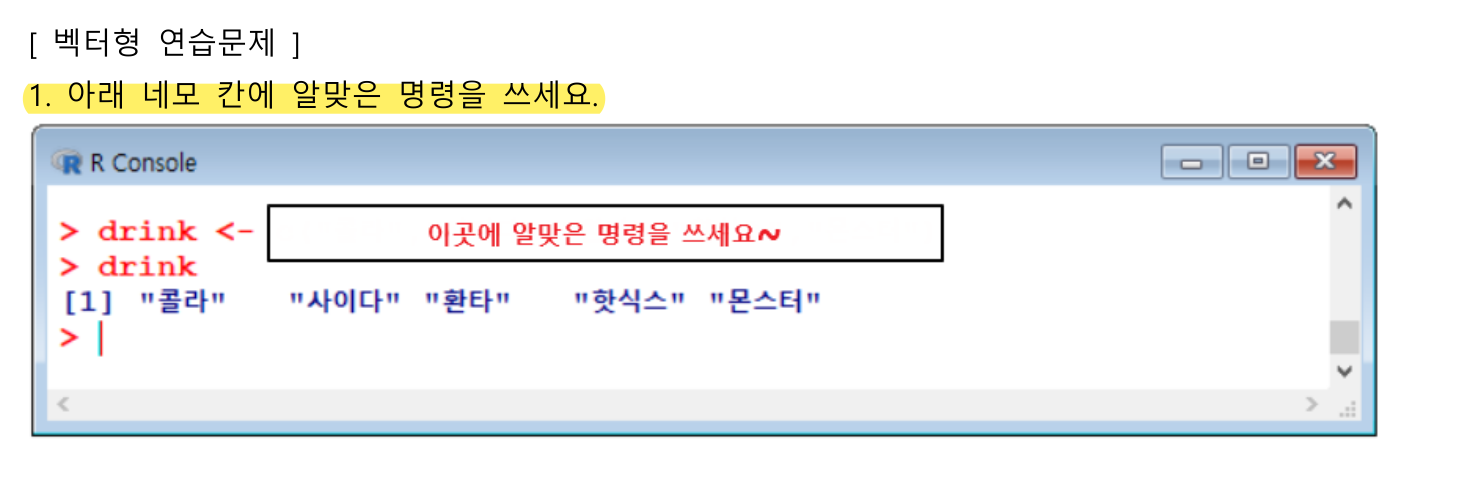
drink <- c('콜라','사이다','환타','핫식스','몬스터')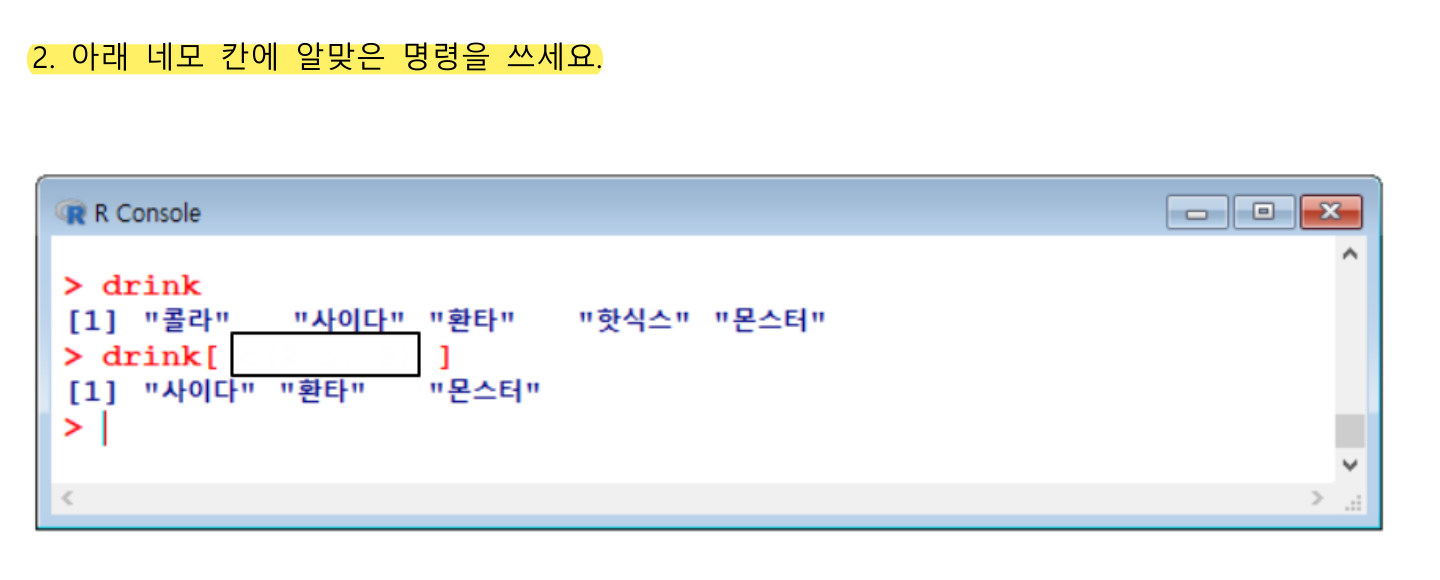
drink[c(2,3,5)]
drink[c(2:3, 5)]
drint[c(-1, -4)]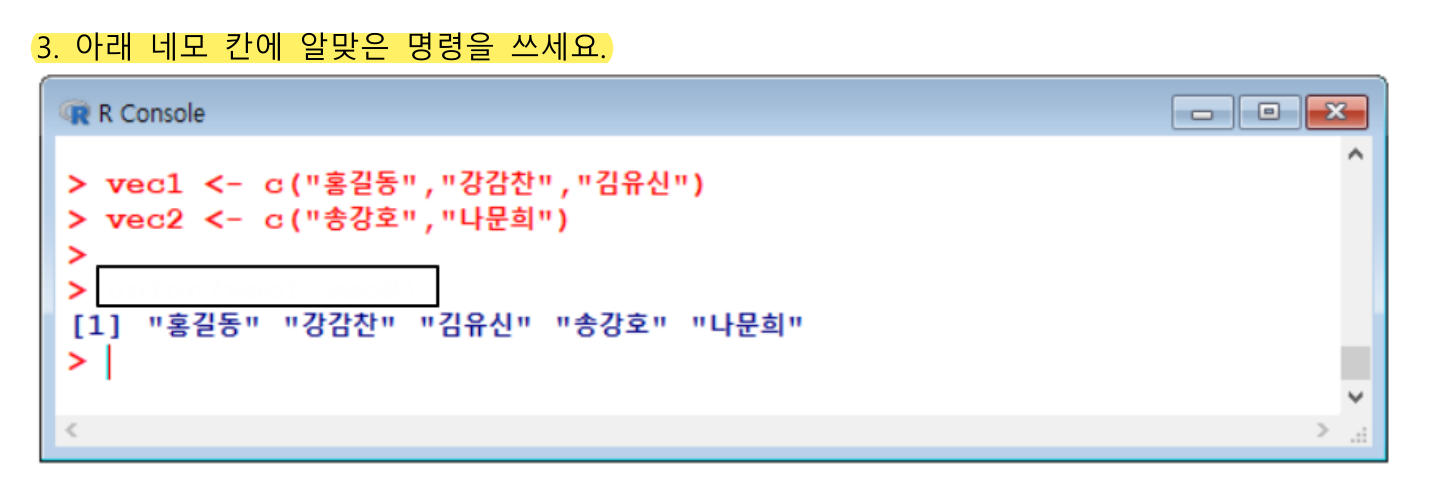
vec3 <- union(vec1,vec2)
vec3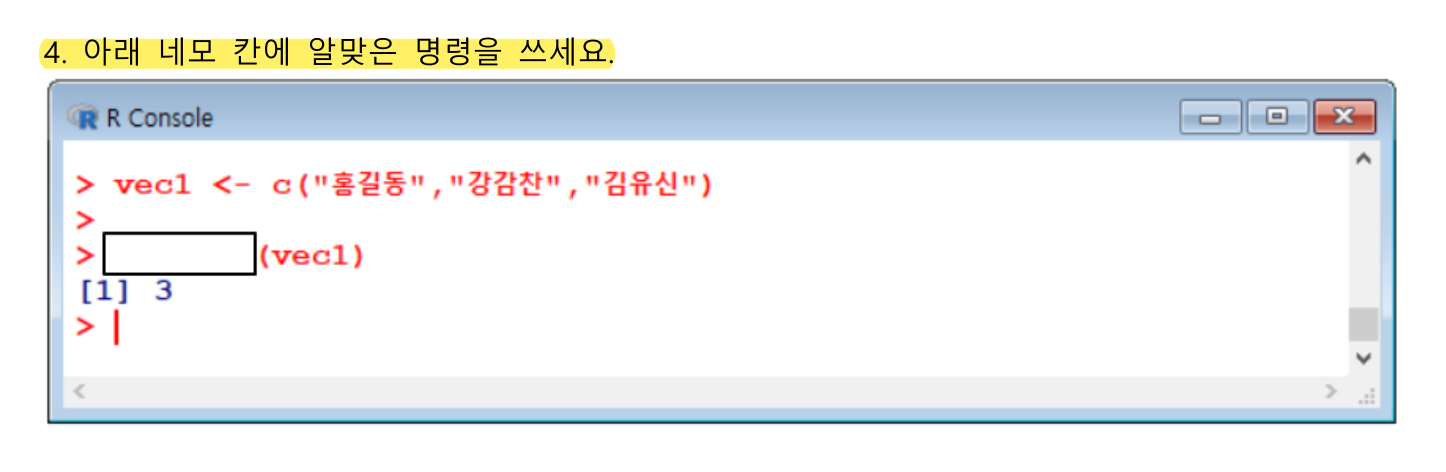
length(vec1)(4) 행렬 Matrix
- 데이터 형태가 2차원으로 행(row)과 열(column)으로 구성됨
- 벡터의 확장개념
- 벡터와 동일하게 하나의 데이터 유형만 가질 수 있음

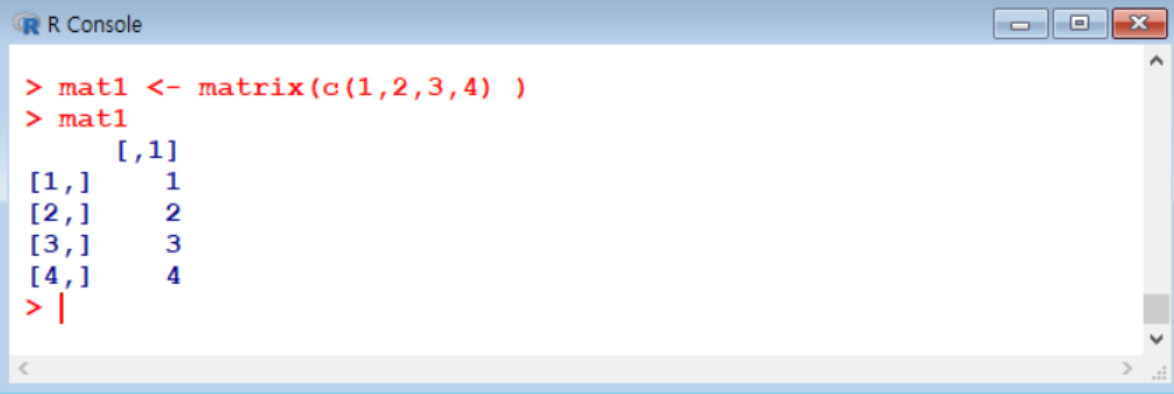
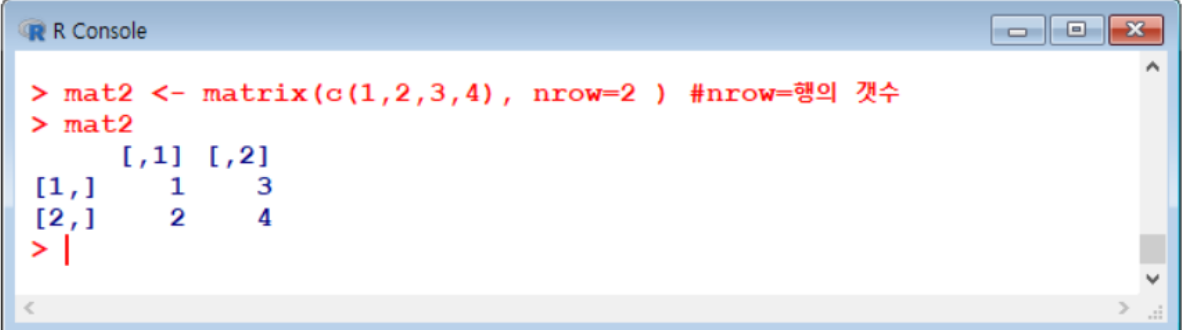
행렬 생성
- matrix 함수 이용
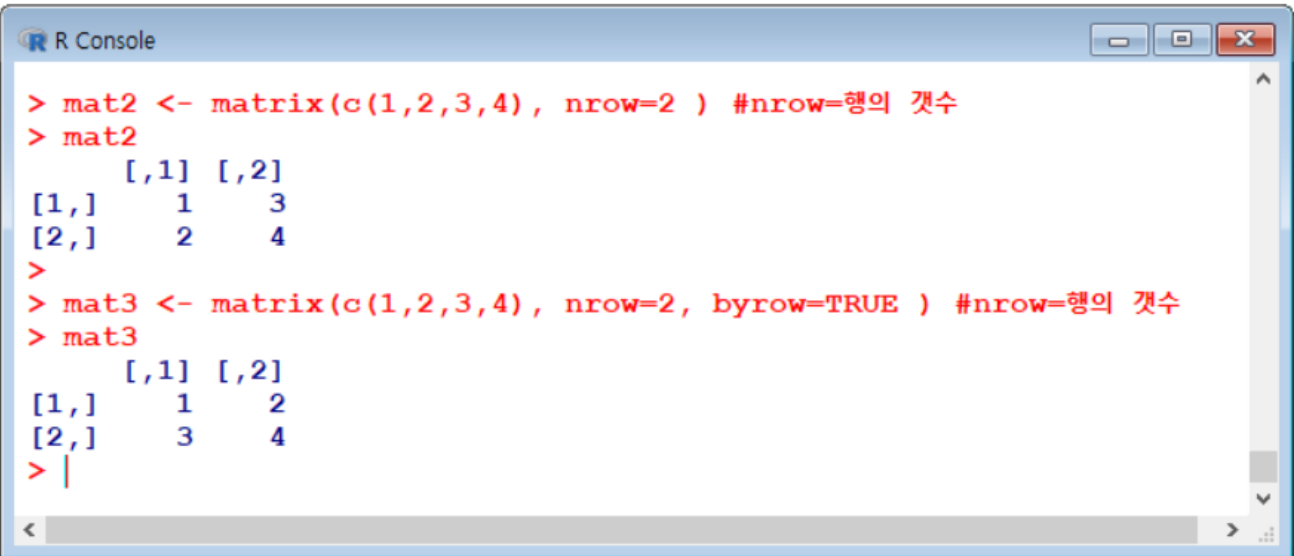
arguemnt 설명 x 벡터를 지정 nrow 행 개수 지정 ncol 열 개수 지정 byrow 행렬에 값이 입력될 때 기본적으로 옆 방향으로 먼저 입력됨. 값이 입력되는 방향을 행 방향으로 수정하고 싶다면 TRUE로 설정 matrix(x, nrow=행개수, ncol=열개수, byrow=FALSE)- rbind() cbind() 이용
rbind(): 벡터를 행 방향으로 합침cbind(): 벡터를 열 방향으로 합침
Matrix사용
Matrix 조회하기
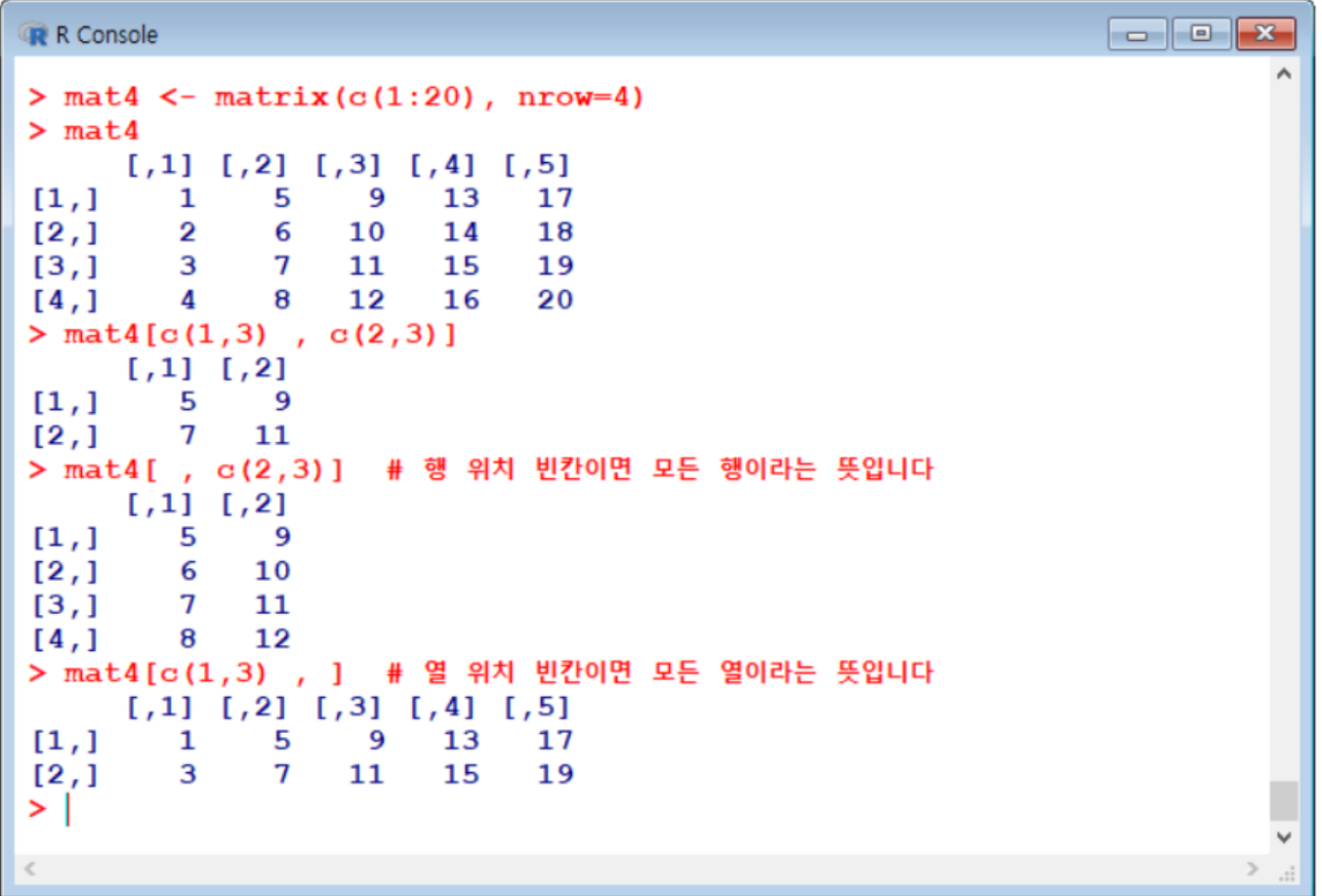
matrix[행번호, 열번호]
💯Matrix 연습문제

fruit <- matrix(c("감자",'고구마','당근','양파'),nrow=2)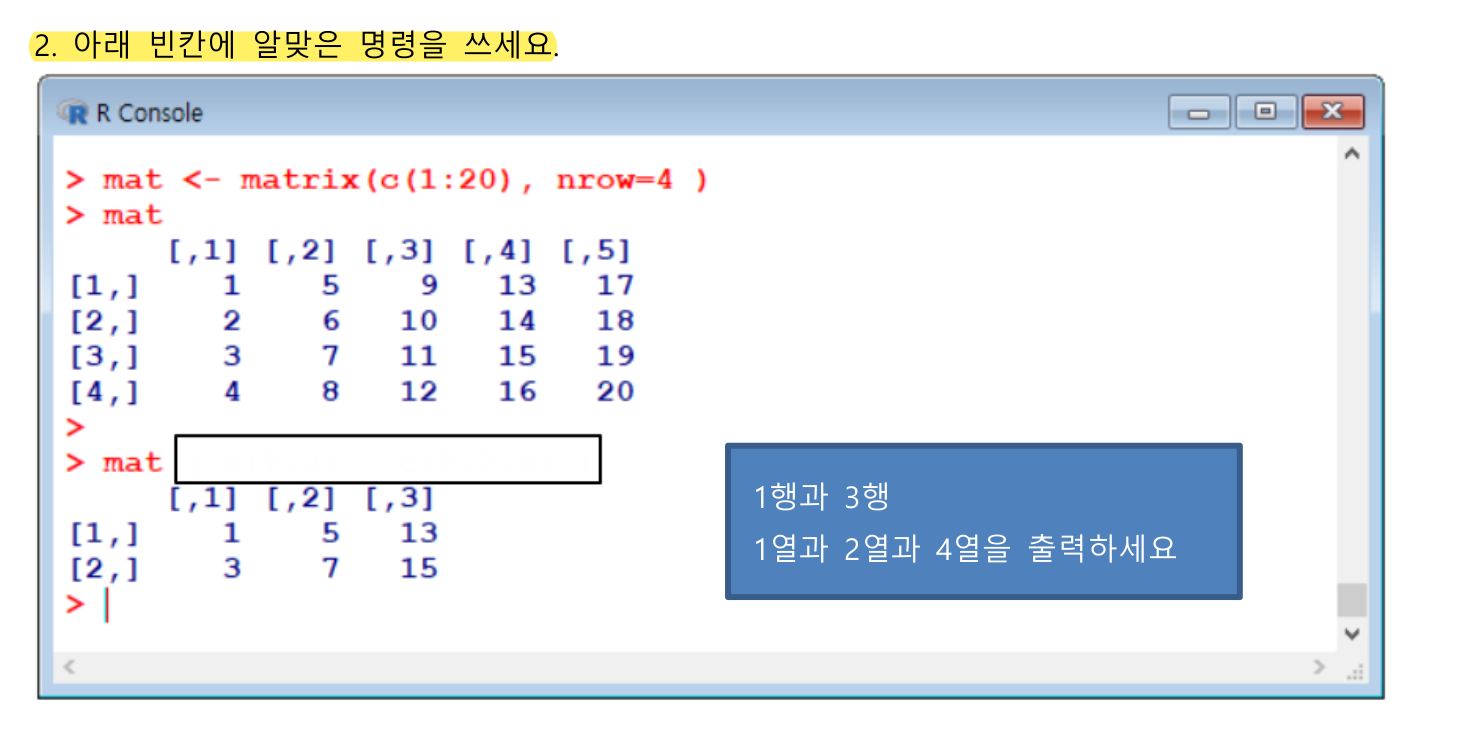
mat[c(1,3),c(1,2,4)]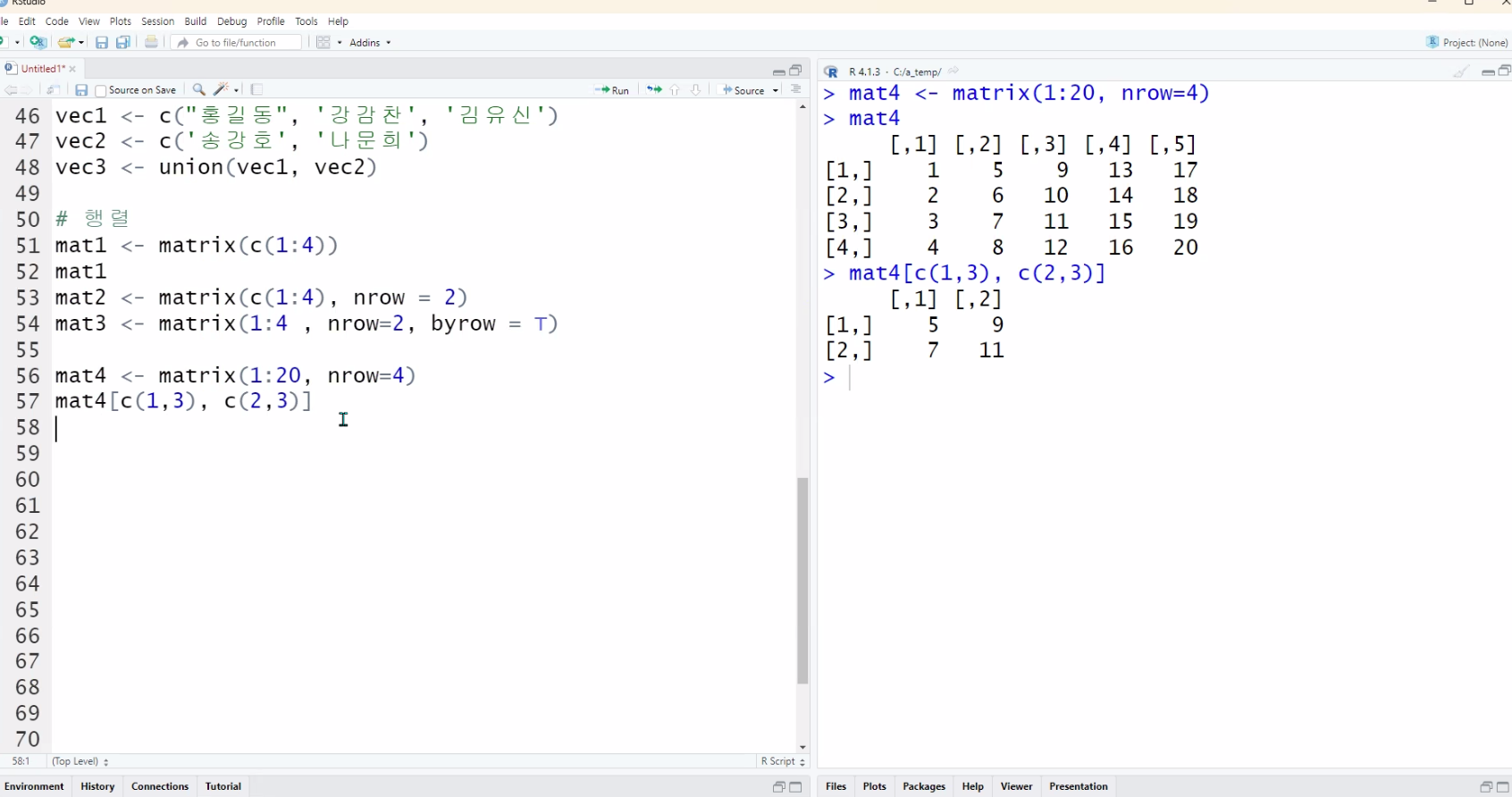
(5) 배열 Array
- vector : 한줄로 저장
- matrix : 가로 x 세로
- array : marix를 쌓음, 즉 가로 x 세로 x 높이

Array 만들기
- array()명령어 이용
- dim 옵션으로 행, 열, 높이 값을 지정
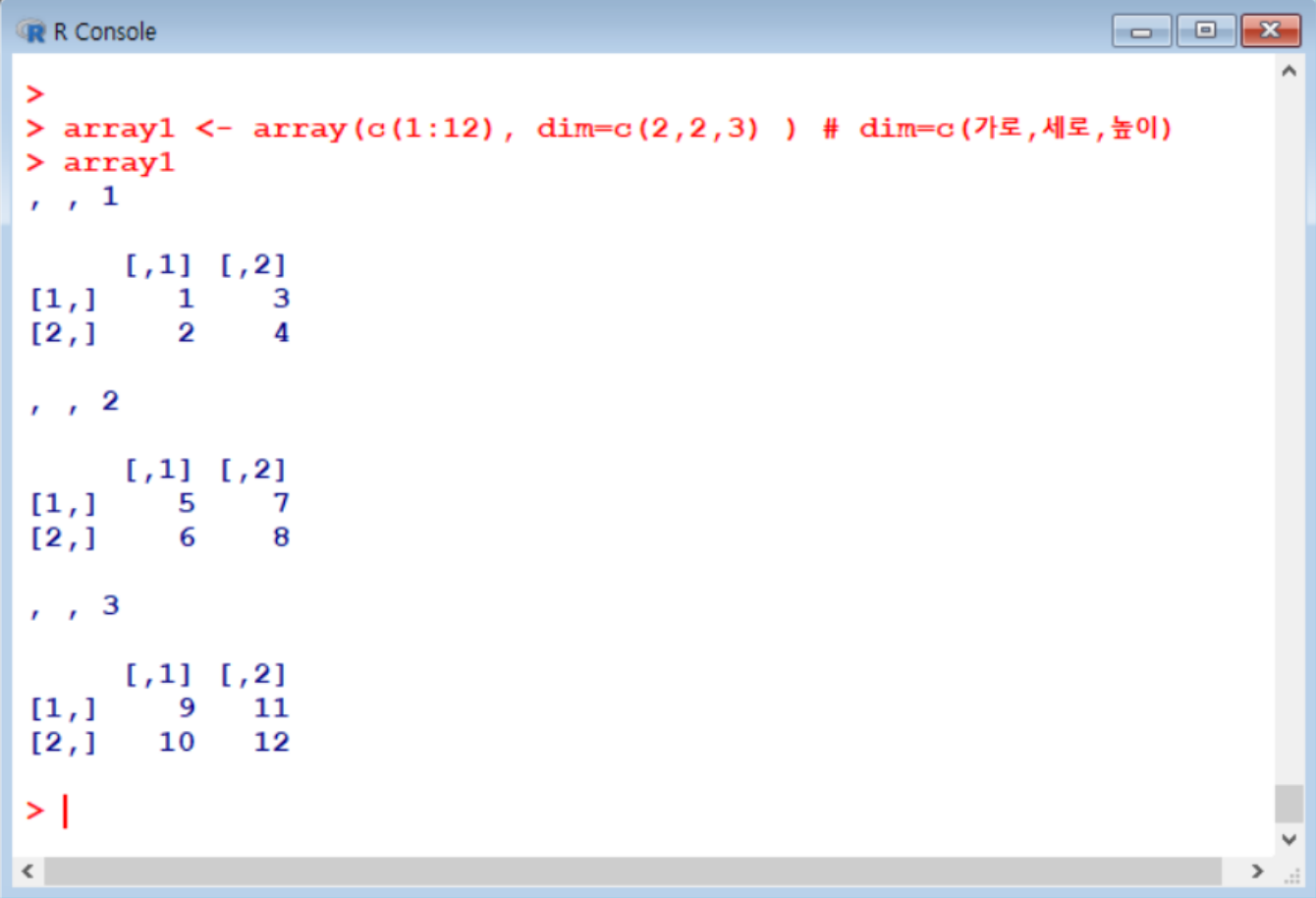
Array 조회하기
array이름[행번호, 열번호, 높이번호]
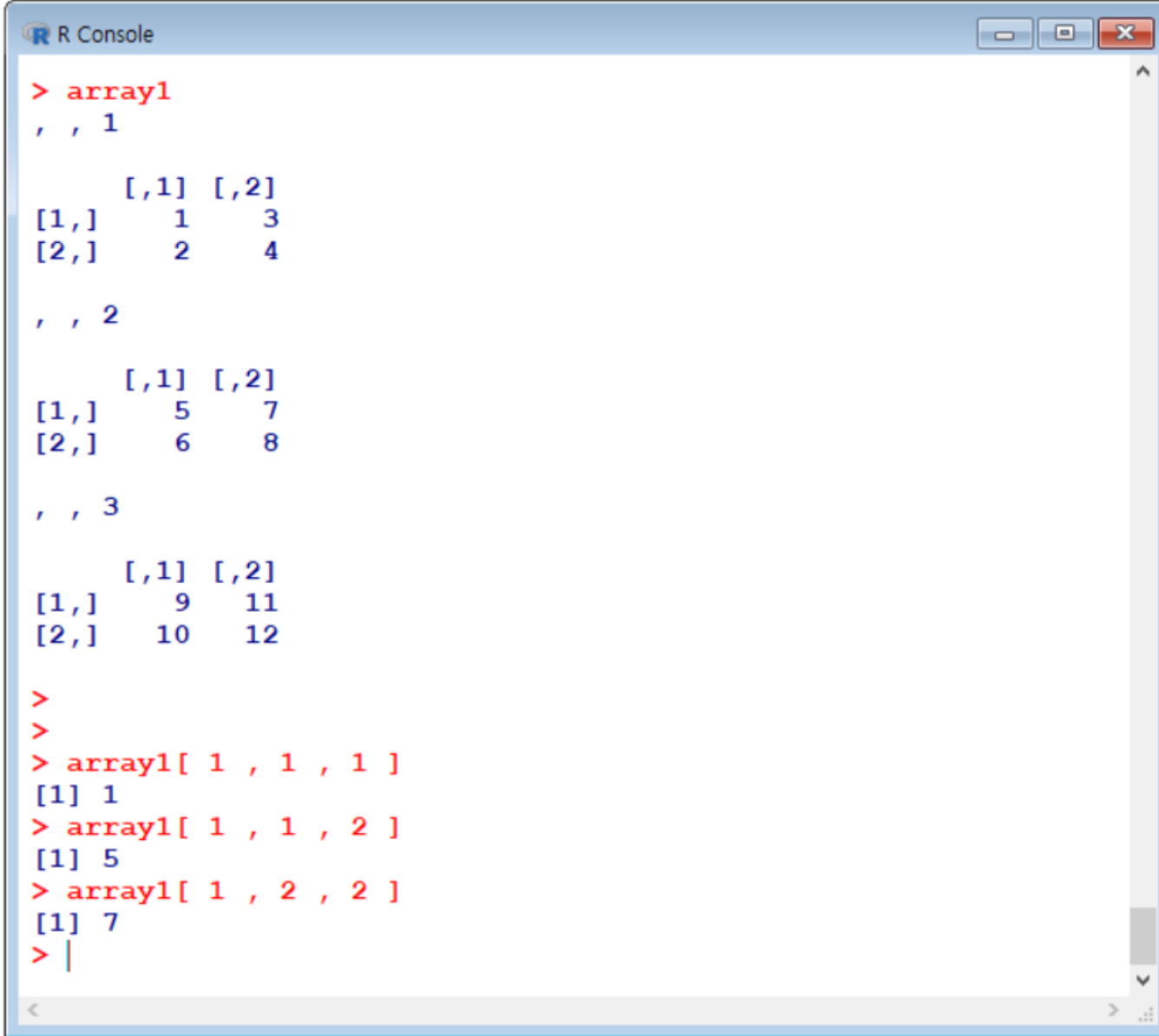
(6) 리스트 list

- 칼럼부분 : Key
- 해당 값 : Value
- key-value 쌍으로 구성
리스트 만드는 법
- list() 함수 사용
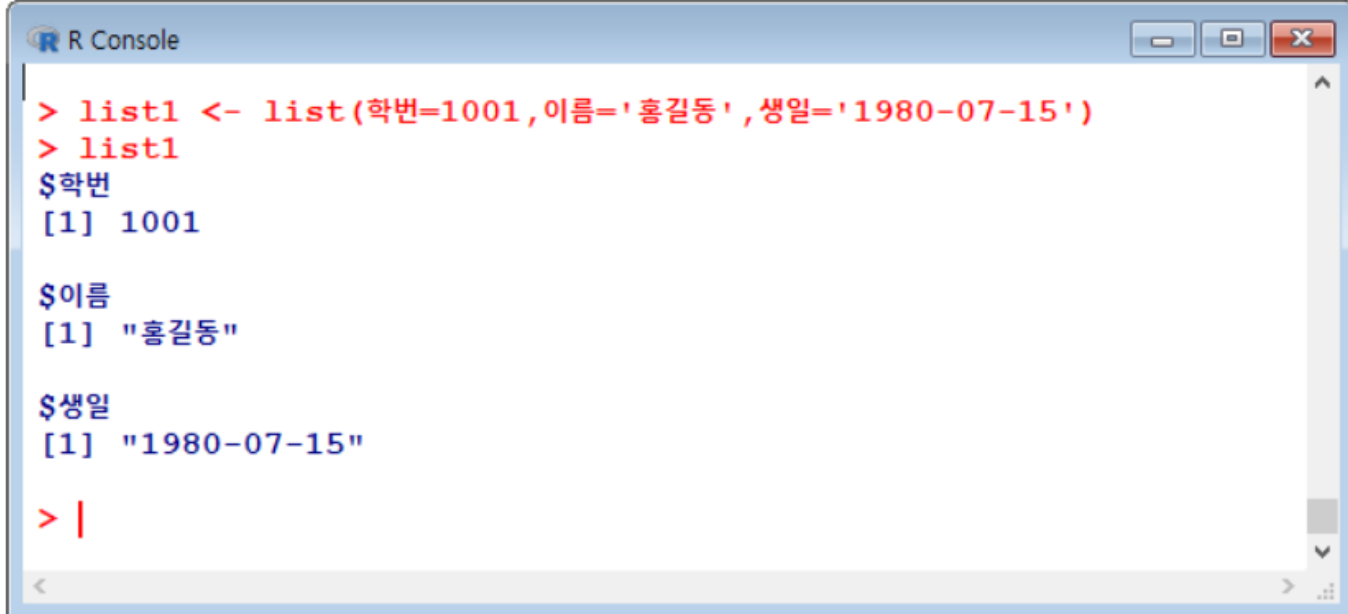
리스트 조회
list이름$key이름
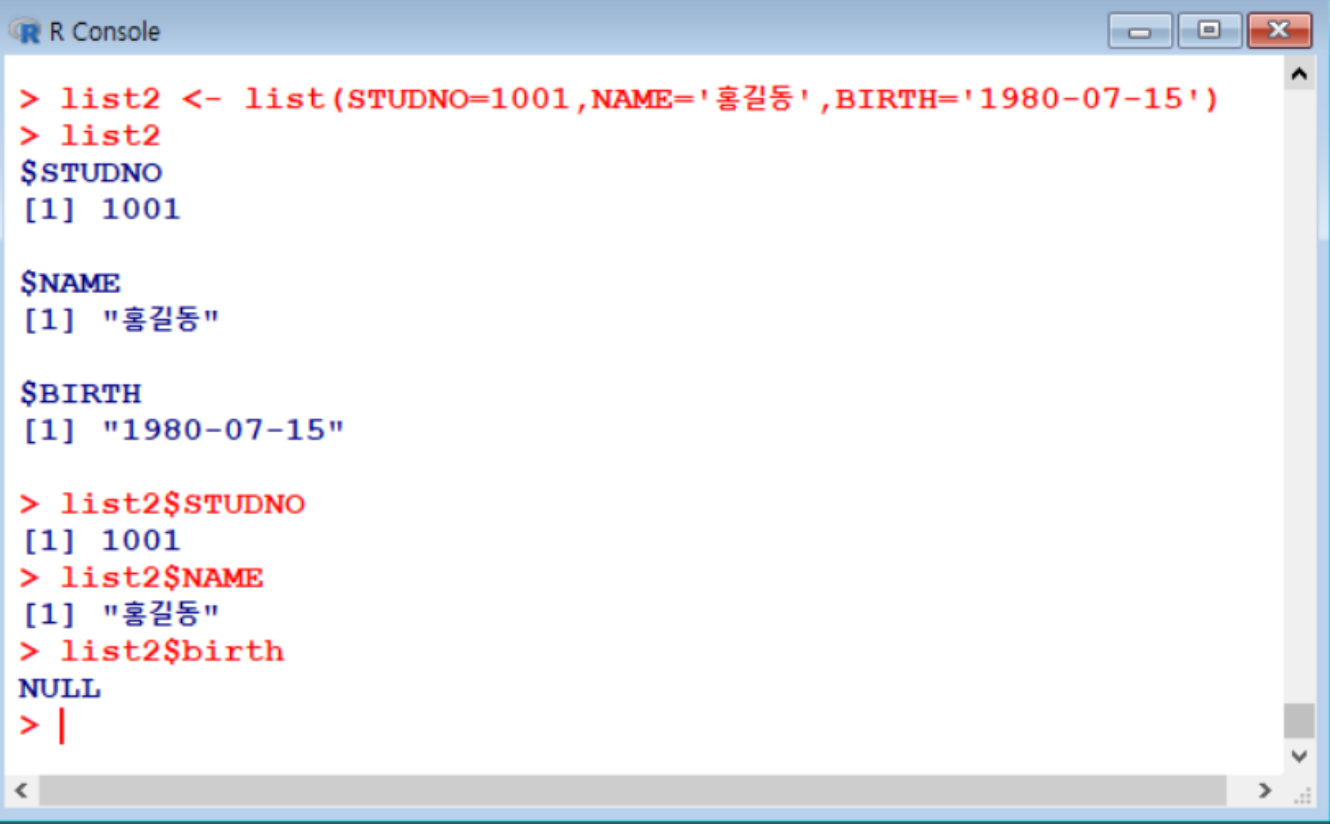
여기서 list2$birth는 조회가 안됨! 대소문자도 구분되기 때문!!
list이름[번호]

💯list 연습문제
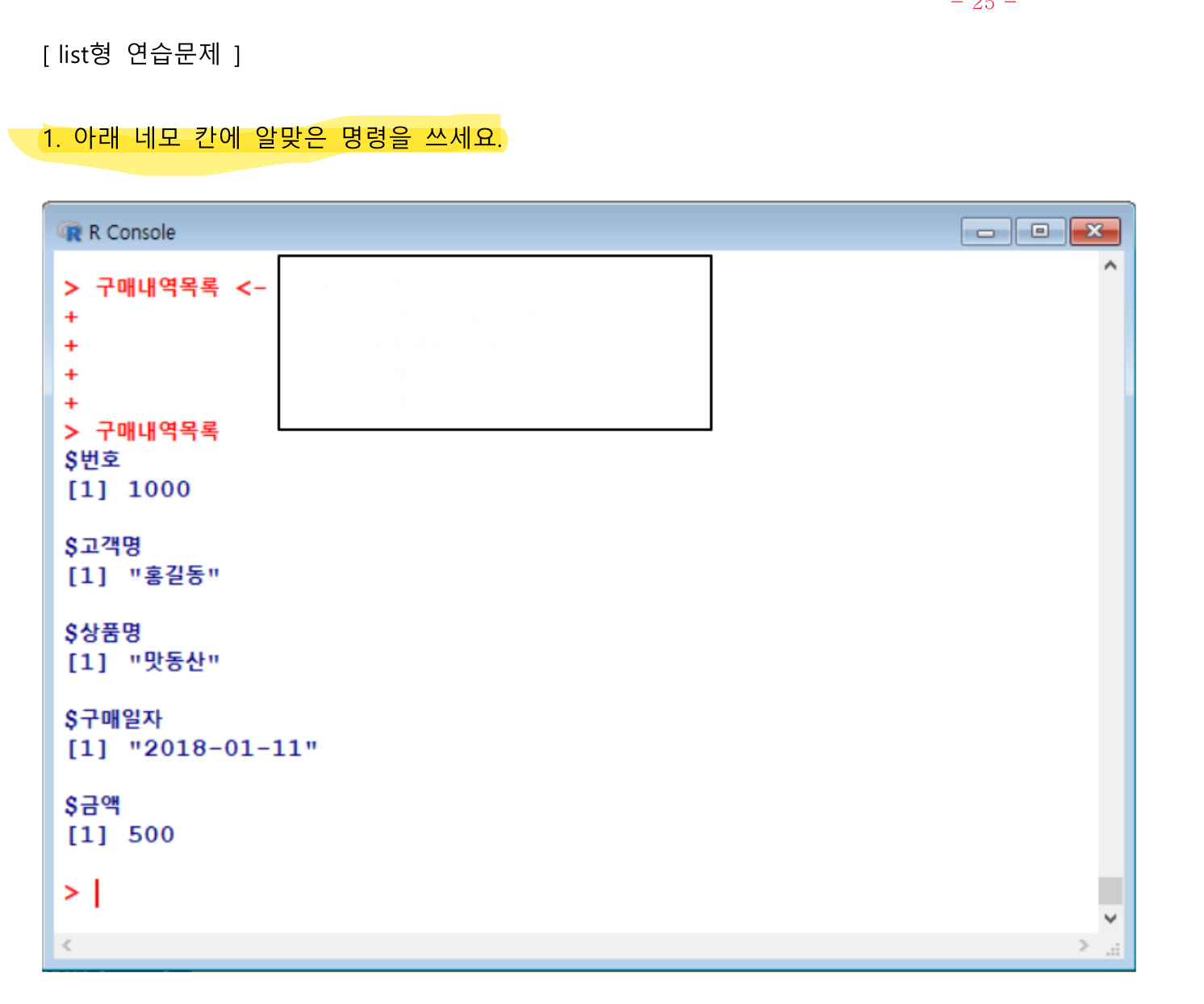
구매내역목록 <- list(번호=1000, 고객명="홍길동", 상품명="맛동산", 구매일자='2018-01-11', 금액=500)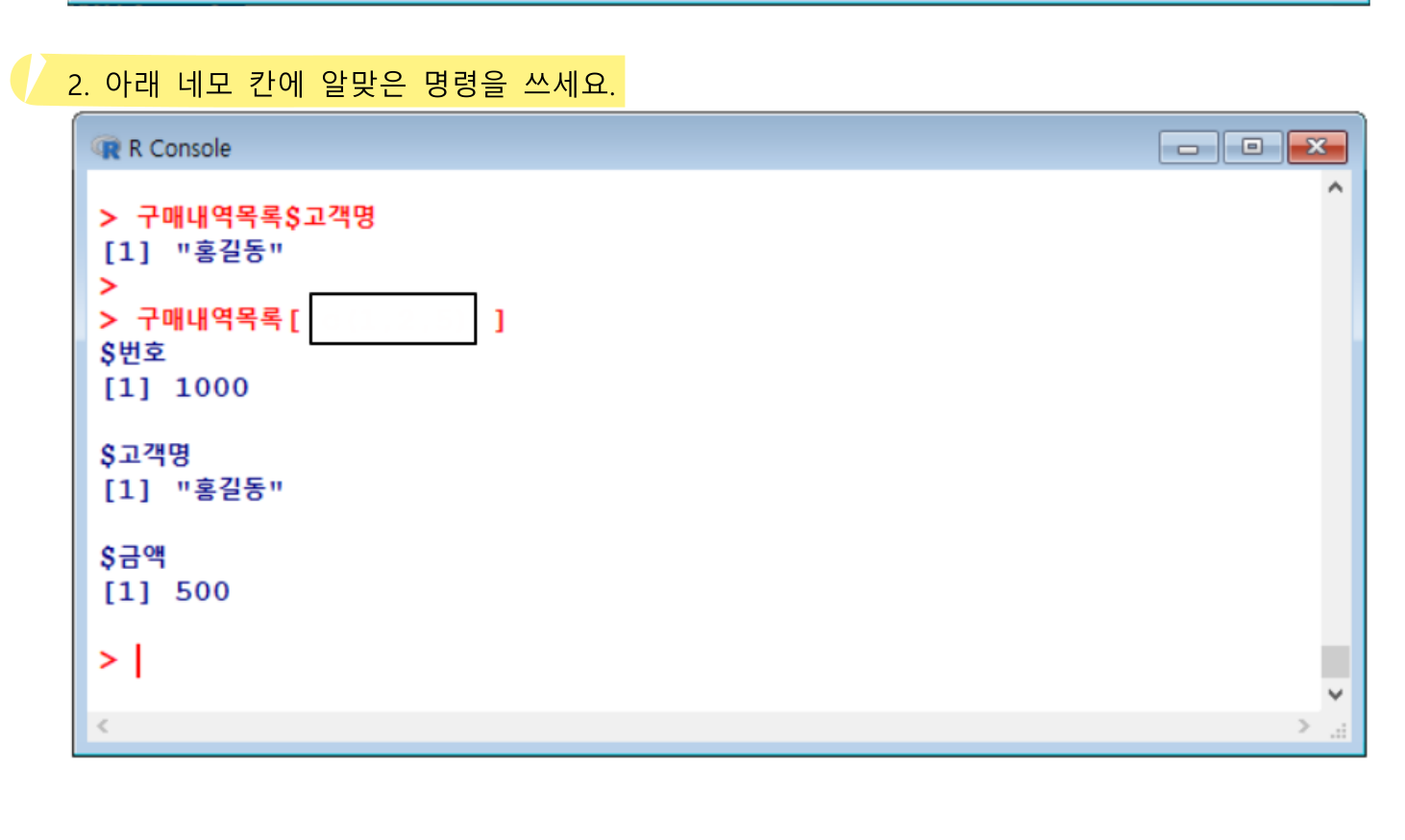
구매내역목록[c(1,2,5)](7) 데이터 프레임 Data Frame
- list 형은 다양한 유형의 데이터를 세트로 만들어서 저장할 수 있는 장점이 있는 반면에 1 건만 저장할 수 있다는 단점
- 실제 현업에서는 다양한 유형의 데이터들을 여러 건을 저장해야 할 경우가 대부분인데 이럴 경우에 사용할 수 있는 유형이 바로 data frame 형
- data frame 유형은 아래 그림처럼 우리가 흔히 말하는 “표” 라고 생각하면 됨
- 컬럼을 “라벨”이라고 부르며 컬럼명을 “라벨명”이라 함
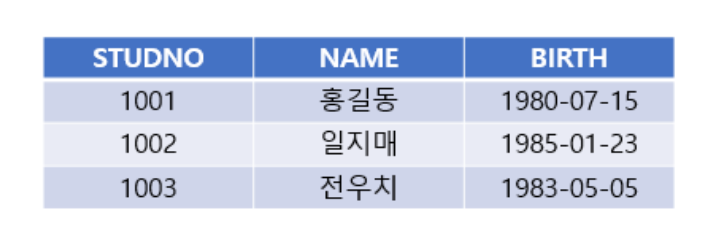
데이터 프레임 만드는 방법

data.frame() 함수 이용
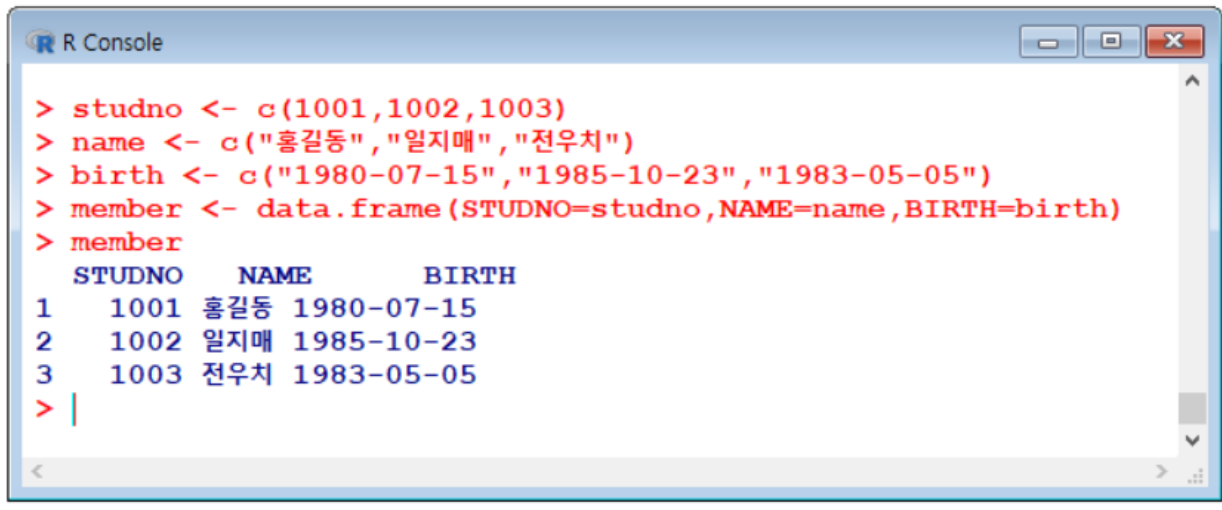
data frame 조회하기
데이터프레임$라벨명
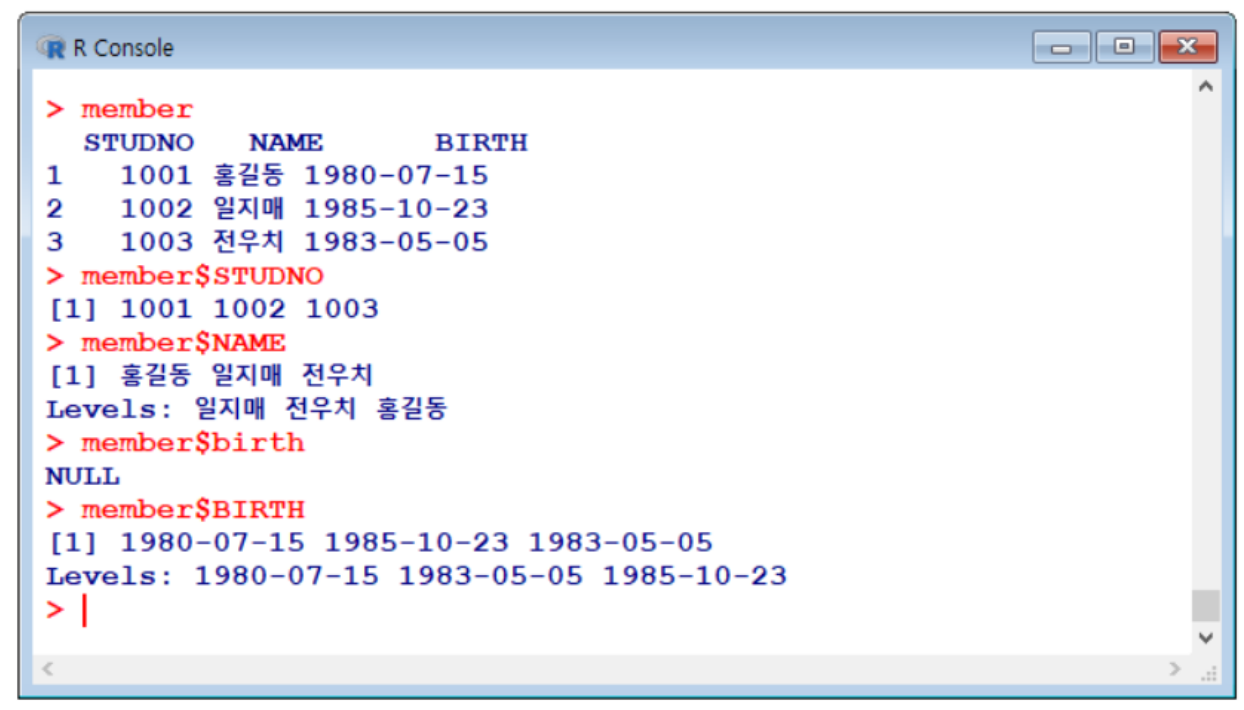
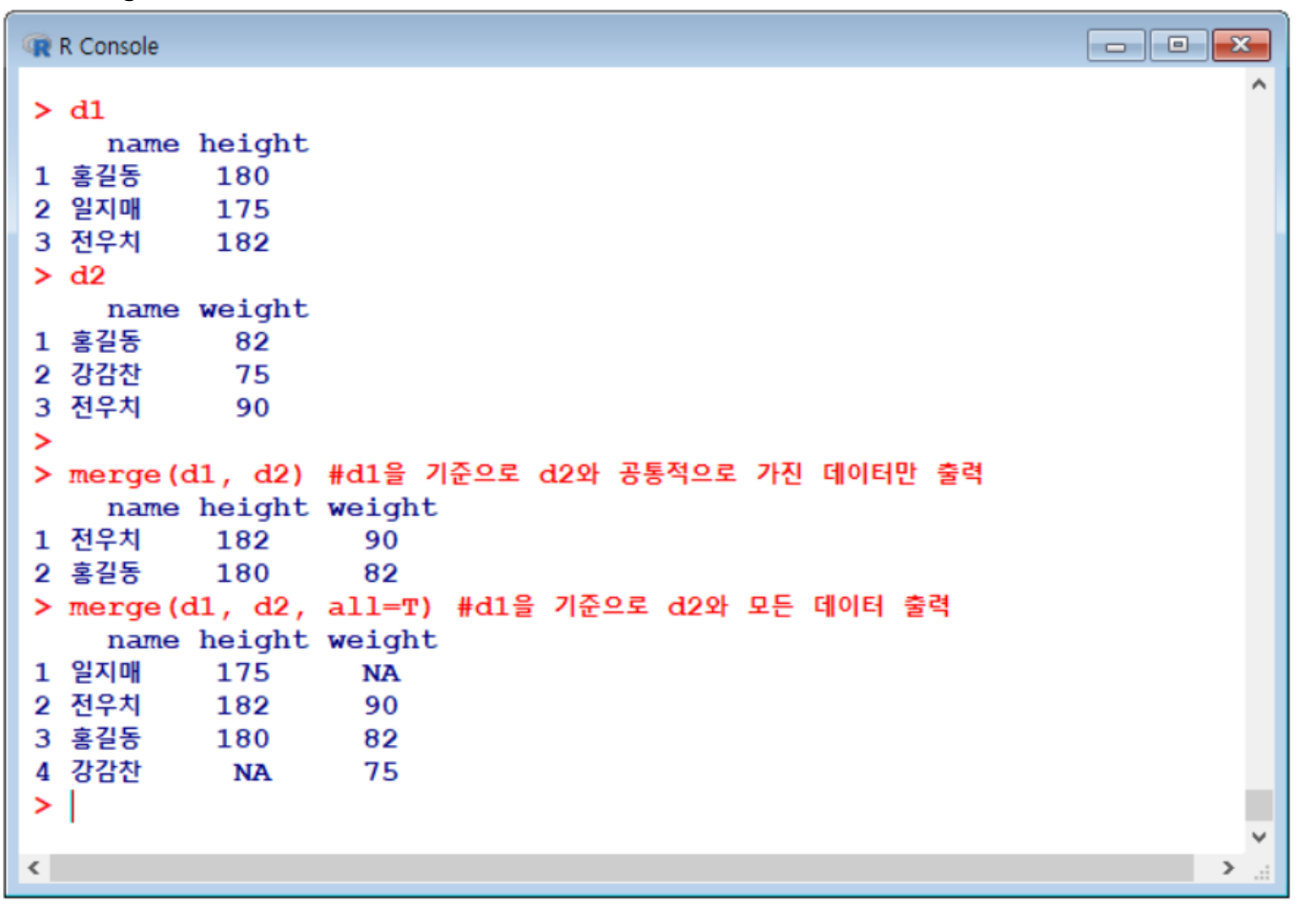
data frame 합치기 - merge
2개의 프레임을 만든 후,
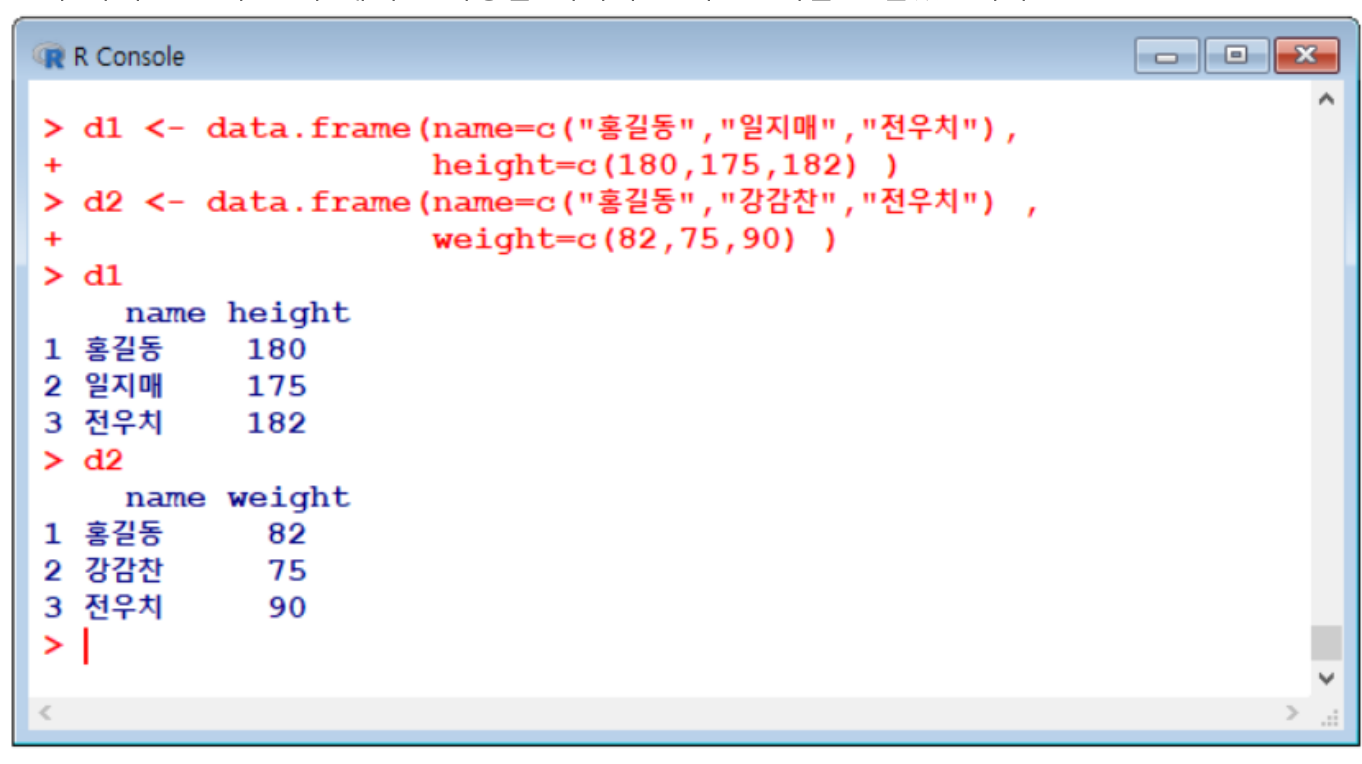
merge함수로 합친다
새로운 행과 열 추가하기
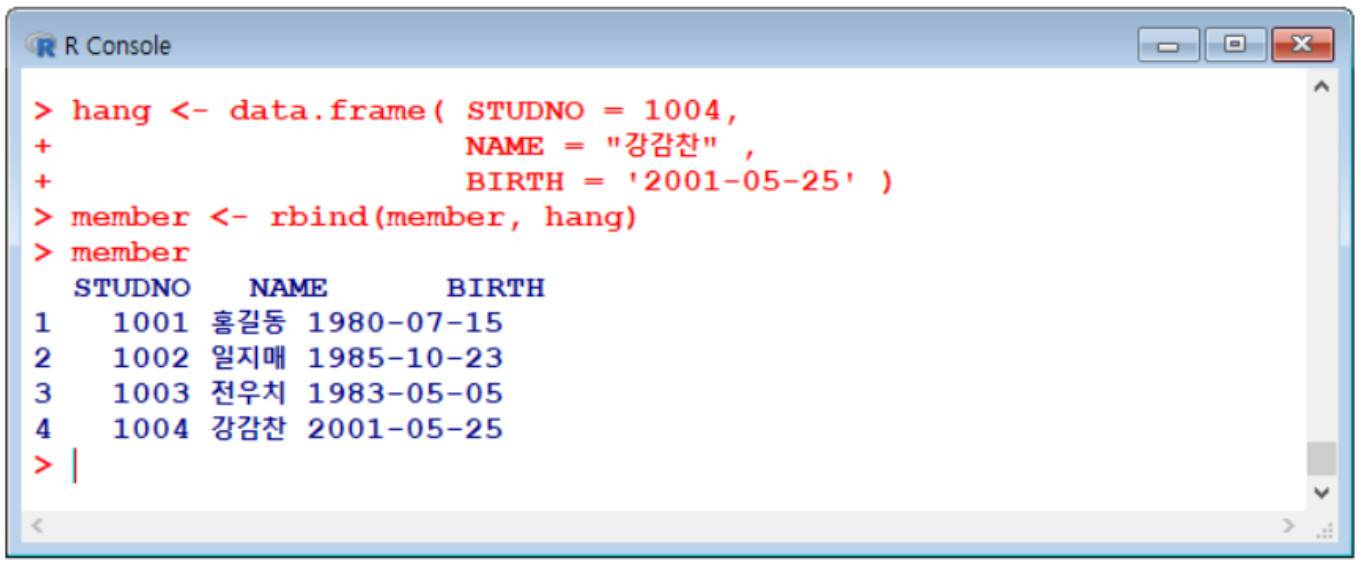
위 그림처럼 마지막에 추가할 행을 기존 데이터 프레임의 형식에 맞도록 변수에 할당한 후에 rbind( ) 함수를 활용해서 추가한다.
이 때 주의 사항은 추가할 행을 만들 때 라벨명을 기존 데이터프레임의 라벨명과 똑같이(대소문자까지) 지정해 주어야 한다.
1. 데이터 프레임
df1 <- data.frame(이름=c('홍길동', '강감찬'),
국어=c(78, 89),
수학=c(68,69))
df1이름 국어 수학
1 홍길동 78 68
2 강감찬 89 69
2. Row 추가 : rbind
df2 <- rbind(df1, list(국어=91, 수학=88, 이름='김유신'))
df2이름 국어 수학
1 홍길동 78 68
2 강감찬 89 69
3 김유신 91 88
2-2. 각 열 확인
df2$국어
[1] 78 89 91df2$수학
[1] 68 69 88
3. Column 추가 : cbind
df3 <- cbind(df2, 총점=c(df2$국어+df2$수학))
df3이름 국어 수학 총점
1 홍길동 78 68 146
2 강감찬 89 69 158
3 김유신 91 88 179
4. 데이터 추가할 때 하나만 넣어도 ncn이 알아서 다 넣어줌
df4 <- cbind(df3, c('ncn'))
df4이름 국어 수학 총점 c("ncn")
1 홍길동 78 68 146 ncn
2 강감찬 89 69 158 ncn
3 김유신 91 88 179 ncn
4-2. 더할 때 개수가 안 맞으면, 전부 다 연산
c(1, 5, 8) + 10
[1] 11 15 18c(1, 5, 8) + c(1, 2, 3)
[1] 2 7 111:3 * 10
[1] 10 20 30
#1,2,3 * 10이니까 !💯Data Frame 연습문제

구매정보테이블 <- data.frame(no=c(1,2,3),
name=c("홍길동", "일지매", "강감찬"),
qty=c(10,20,30))
구매정보테이블no name qty
1 1 홍길동 10
2 2 일지매 20
3 3 강감찬 30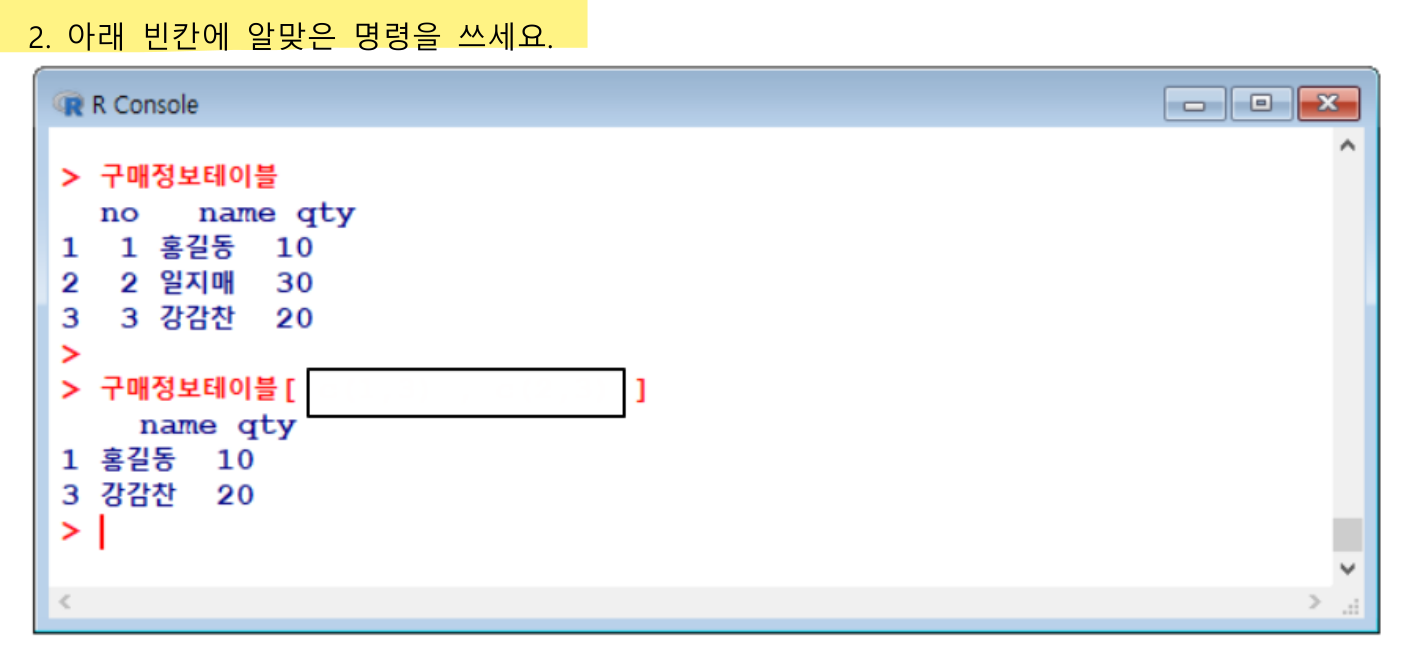
구매정보테이블[c(1,3),c(2,3)]구매정보테이블[c(1,3),c(2:3)]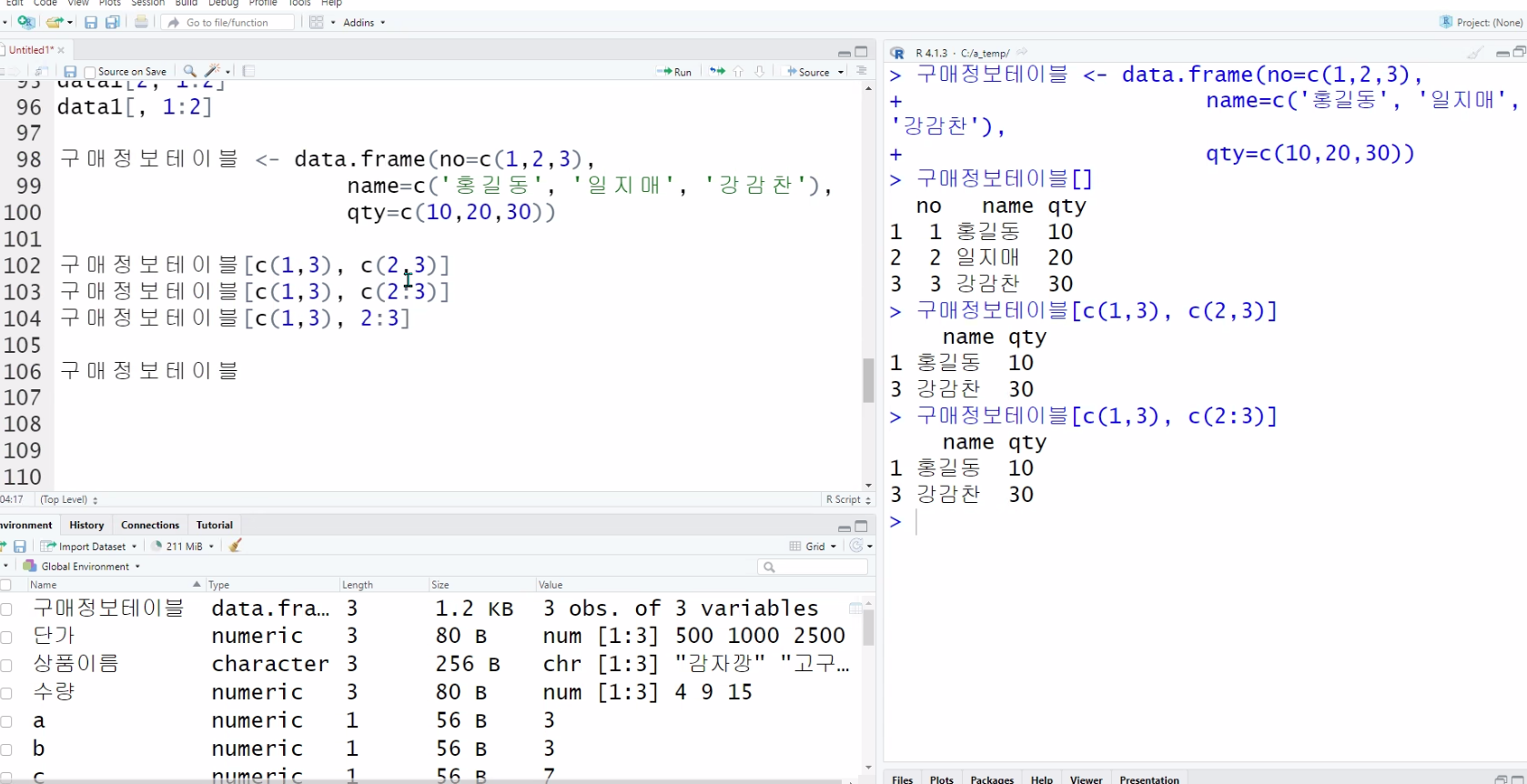
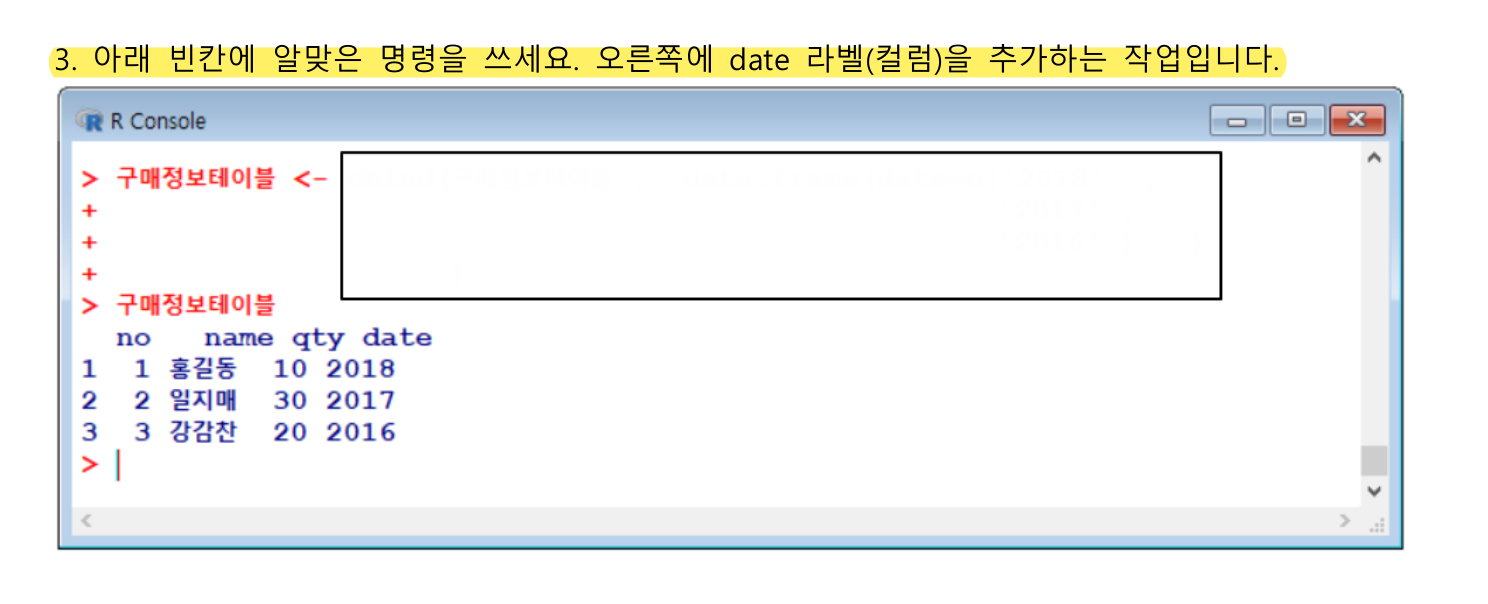
구매정보테이블 <- cbind(구매정보테이블, date=c(2018:2016))
구매정보테이블구매정보테이블
no name qty date
1 1 홍길동 10 2018
2 2 일지매 20 2017
3 3 강감찬 30 20164. 데이터 불러오기와 저장하기
(1) 비정형 데이터 불러오기 : readLines()
C://a_temp or C:/a_temp
- 읽어오기: readLines()
- 쓰기 : writeLines()
예시: 구매후기.txt

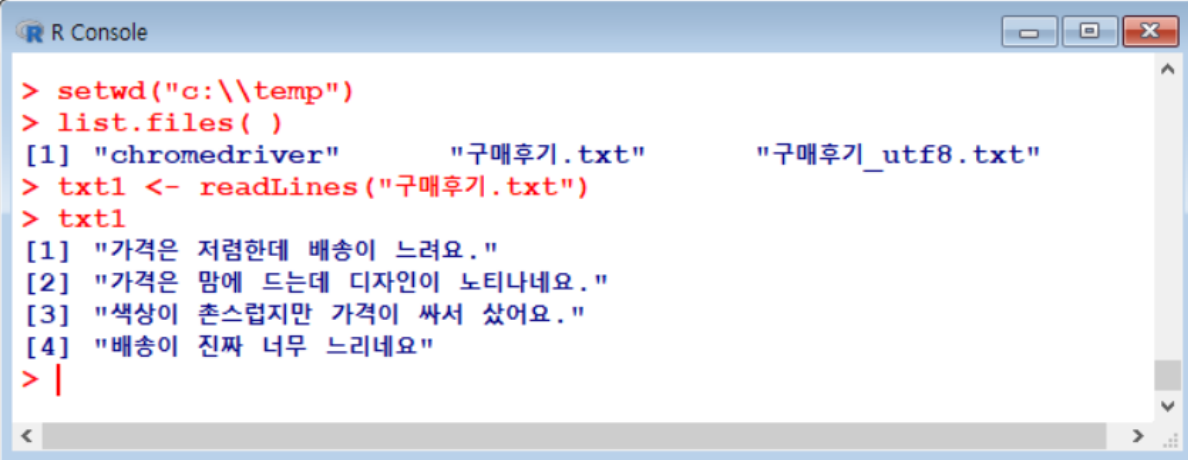
- readLines 인코딩 문제
- ANSI
- UTF_8
txt1 <- readLines("구매후기.txt")
txt1txt2 <- readLines("구매후기_utf8.txt")
txt2
> txt2
[1] "媛\u0080寃⑹<9d>\u0080 <ec><a0>\u0080<eb>졃<ed>븳<eb>뜲 諛곗넚<ec><9d>\u0080 <eb>뒓<eb>젮<ec>슂. "
[2] "媛\u0080寃⑹<9d>\u0080 留덉쓬<ec>뿉 <eb>뱶<eb>뒗<eb>뜲 <eb>뵒<ec>옄<ec>씤<ec>씠 <eb>끂<ed>떚<eb>굹<eb>꽕<ec>슂."
[3] "<ec>깋<ec>긽<ec>씠 珥뚯뒪<eb>읇吏\u0080留<8c> 媛\u0080寃⑹씠 <ec>떥<ec>꽌 <ec><83>\u0080<ec>뼱<ec>슂."
[4] "諛곗넚<ec>씠 吏꾩쭨 <eb>꼫臾<b4> <eb>뒓由щ꽕<ec>슂."이렇게 외계어처럼 나오는 현상은 인코딩이 달라서 생기는 현상!!
이럴 때에는 encoding="UTF-8" 을 추가하기
txt2 <- readLines("구매후기_utf8.txt", encoding="UTF-8")
txt2
[1] "가격은 저렴한데 배송은 느려요. "
[2] "가격은 마음에 드는데 디자인이 노티나네요."
[3] "색상이 촌스럽지만 가격이 싸서 샀어요."
[4] "배송이 진짜 너무 느리네요."(2) 정형 데이터 불러오기
read.table()
example) 전공.txt

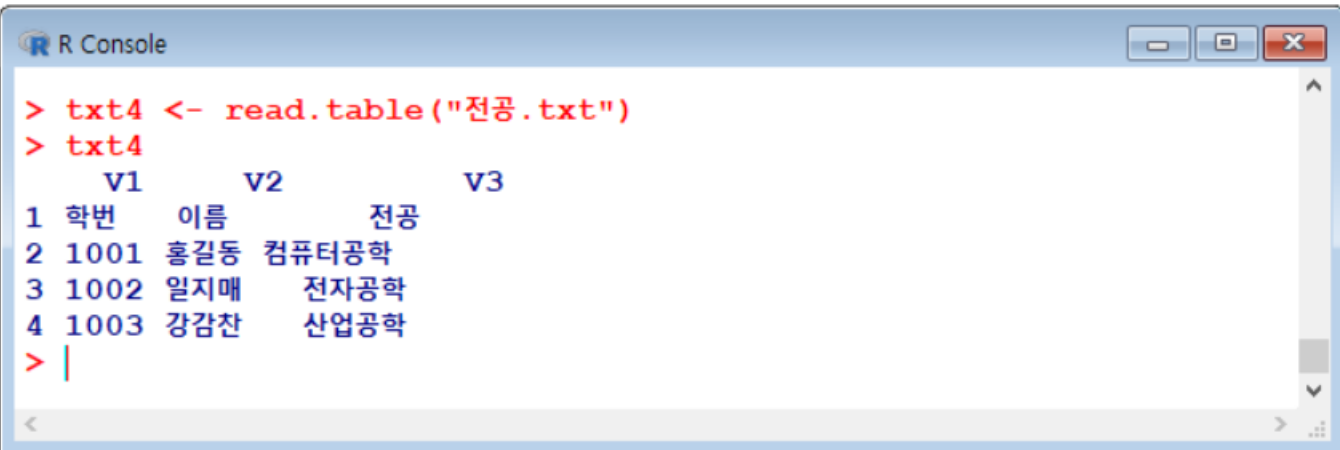
- 위에 붙는 V1, V2, V3는 자동으로 붙은 컬럼이름!
- 이 부분이 나오지 않길 원하면 옵션으로
header=TRUE추가
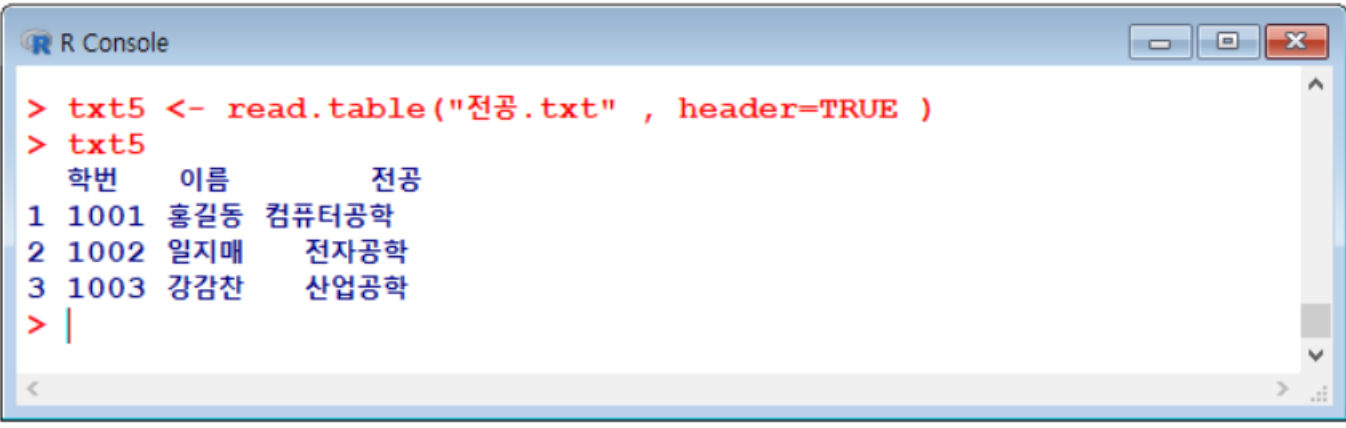
- 컬럼을 특정 기호별로 구분하고자 한다면,
sep옵션 활용하기- example. 전공2.txt

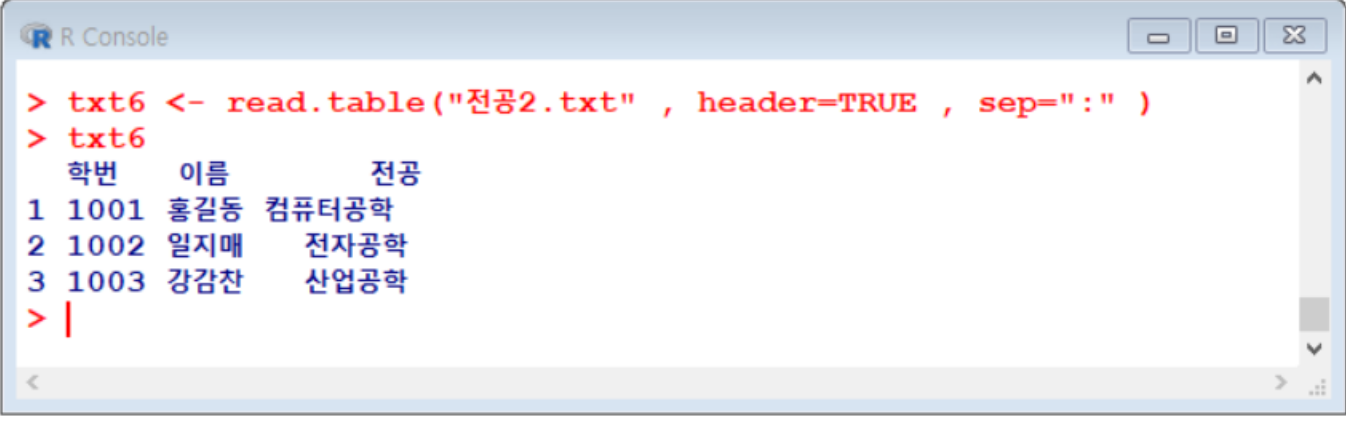
- 이때 데이터 양이 너무 많을 경우,
read.table()보다는data.table()명령어가 더 빠르다는 것 참고
👉 read.csv()란?
컬럼의 구분이 , (콤마기호) 로 저장되어 있는 파일
엑셀 파일을 저장 할 때나 다양한 인터넷에서 표 형태의 데이터를 저장할 때 아주 많이 사용하는 유형의 파일


readxl()
- 실무에서 excel 로 저장된 데이터를 불러와서 작업해야 할 때, excel 형식 파일 불러옴
- readxl( ) 패키지는 기본적으로 설치가 안 되어 있기 때문에 독자님이 직접 추가로 설치를 해야함
> install.packages(“readxl”)
> library(“readxl”)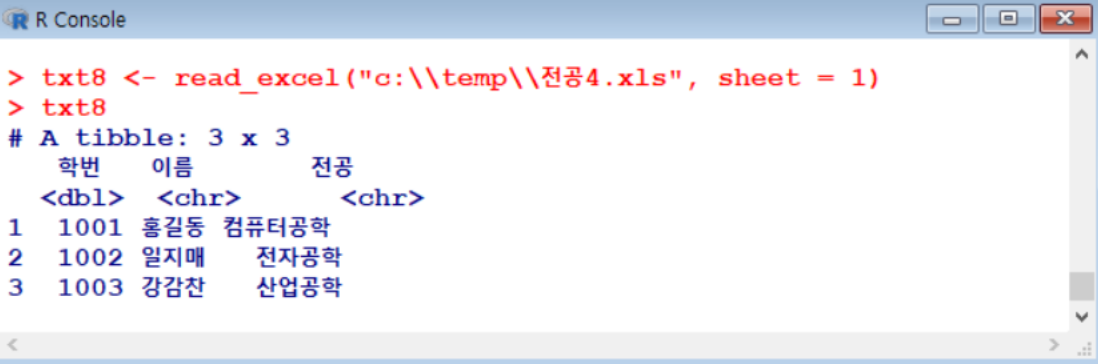
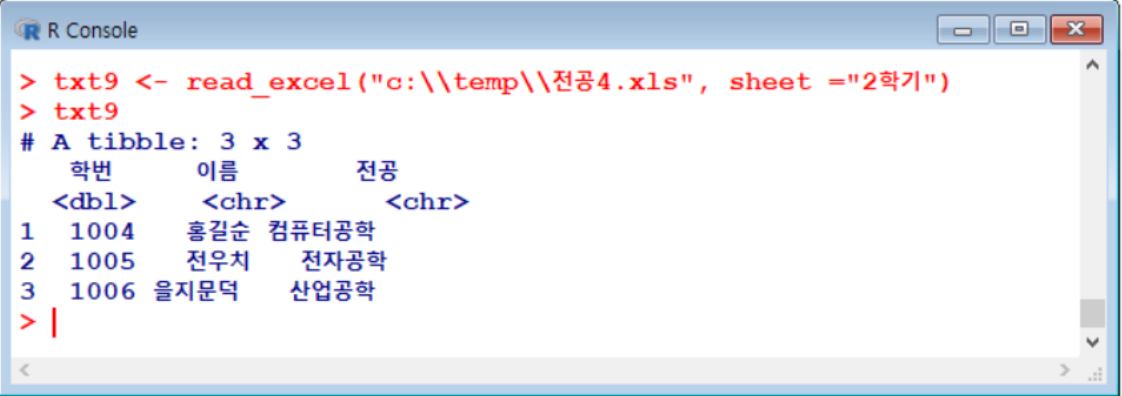
- sheet 옵션으로 sheet 이름 지정하는 것도 가능xls, xlsx 형식 모두 가능
(3) 사용자로부터 데이터 입력 받기
scan()함수 → 숫자나 단어 입력받기
- 간단한 숫자나 단어 입력
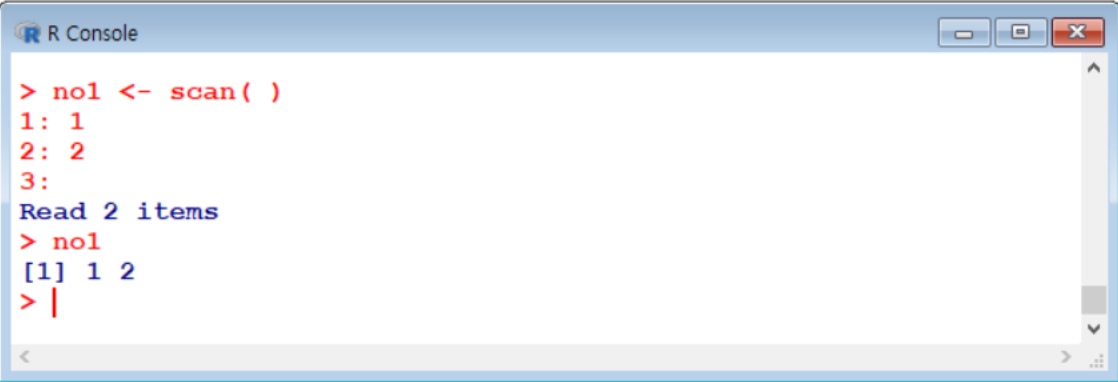
- 문자나 날짜 입력 :
what=””옵션 사용
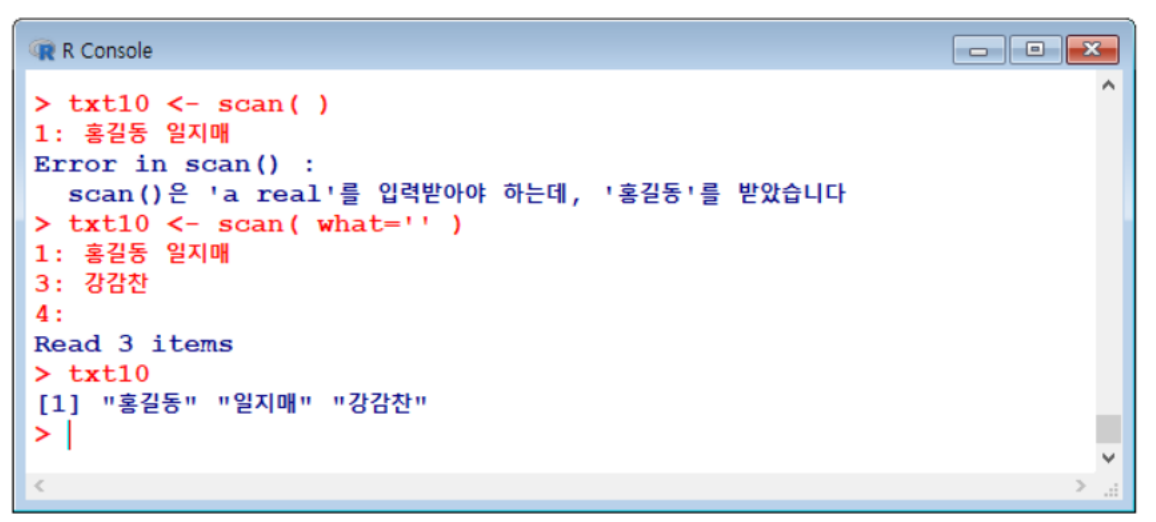
readline()→ 문장 입력 받기
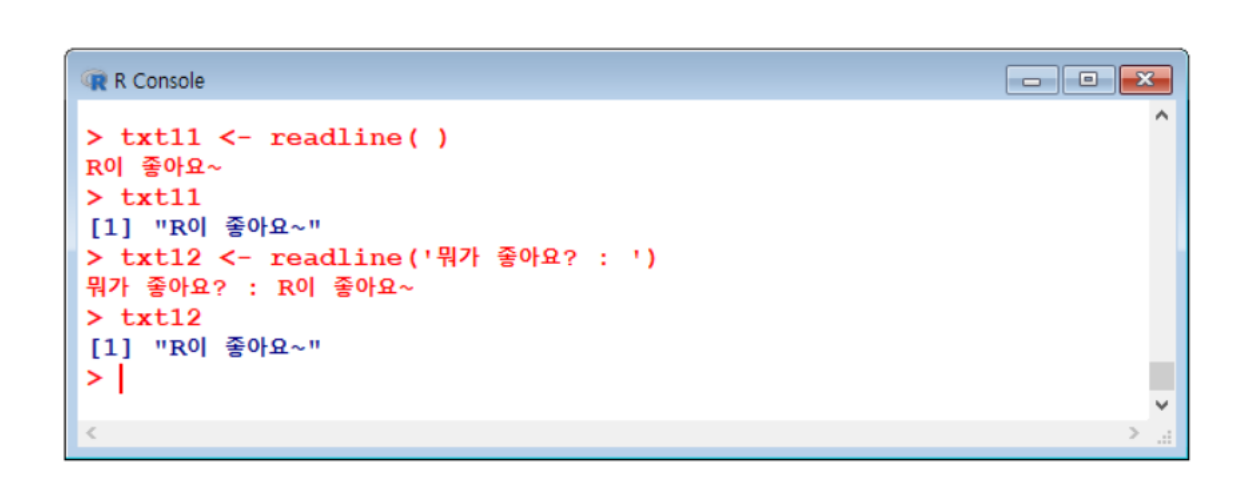
입력할 문장을 후 엔터를 치면 나온다.
이외로 pdf, SPSS, SAS 파일 등 불러올 수 있다.
(4) 저장하기
write( )/writeLines( )- 비정형 형태로 저장하기
- 비정형 데이터 불러오기 :
readLines() - 비정형 형태로 저장하기 :
write()나writeLines()

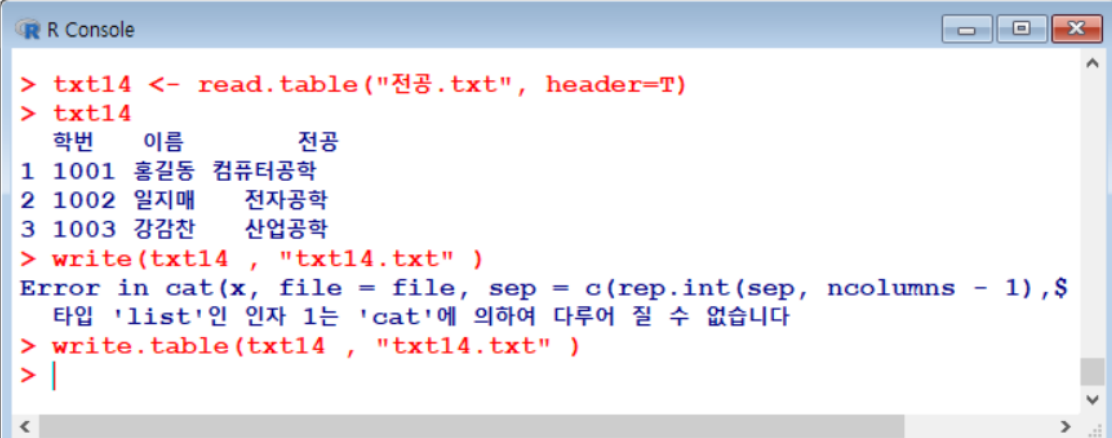
write.table( )– 공백으로 구분된 테이블 형태로 저장하기
- 테이블 형태 데이터 불러오기 :
read.table() - 테이블 형태로 저장하기 :
write.table() - 결과:

write.csv()– csv 형태로 저장하기
- csv 형식 읽어올 때:
read.csv() - csv형식으로 저장할 때 :
write.csv()
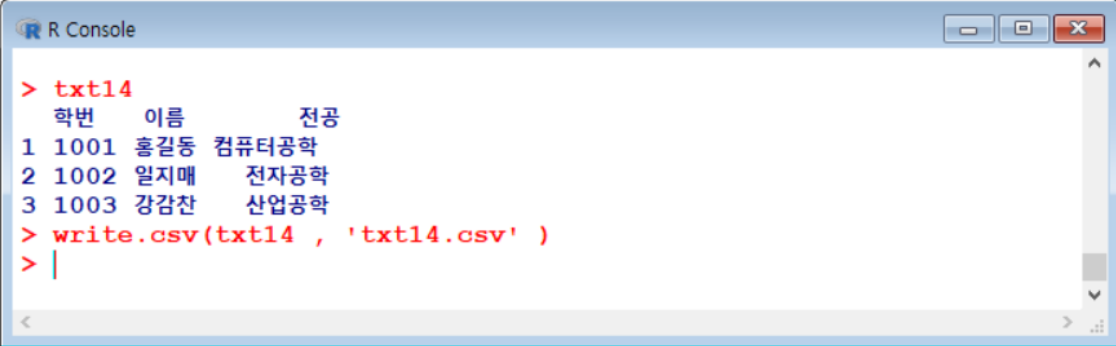

저장하면 구분이 콤마로 되어 있음.
엑셀 (xls , xlsx) 형식으로 저장하기
> install.packages(“xlsx”)
> library(“xlsx”)위 패키지 설치 후, 아래 명령어 실행
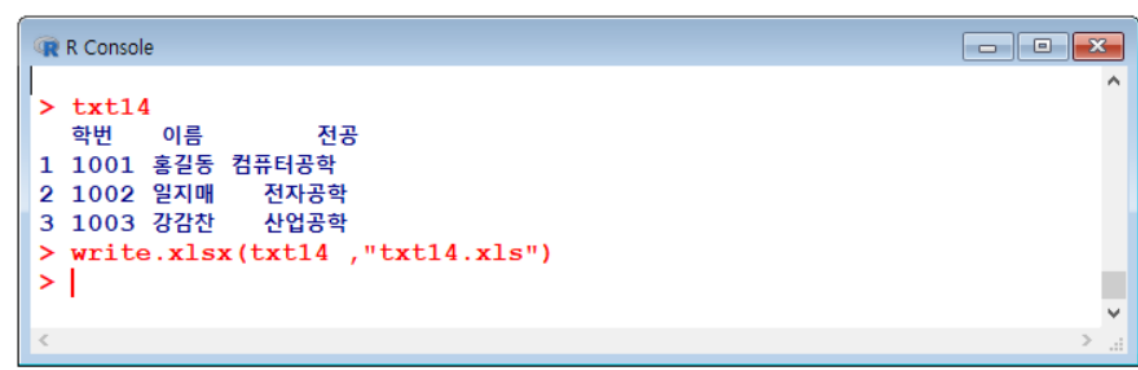
그림 저장하기
example) 경상남도 2015 예산.csv
> # 경상남도 2015 예산
> data1 <- readLines("경상남도_2015_예산.csv")
> data1
[1] "총예산,세부지출,예산" "총수입,기타,2254"
[3] "총수입,복지노인정책과,1066" "총수입,예산담당관,1021"
[5] "총수입,여성가족정책관,710" "총수입,세정과,499"
[7] "총수입,도로과,471" "총수입,수질관리과,358"
[9] "총수입,하천과,284" "총수입,농업정책과,218"
[11] "총수입,친환경농업과,198"> data1 <- read.csv("경상남도_2015_예산.csv")
> data1
총예산 세부지출 예산
1 총수입 기타 2254
2 총수입 복지노인정책과 1066
3 총수입 예산담당관 1021
4 총수입 여성가족정책관 710
5 총수입 세정과 499
6 총수입 도로과 471
7 총수입 수질관리과 358
8 총수입 하천과 284
9 총수입 농업정책과 218
10 총수입 친환경농업과 198> str(data1)
'data.frame': 10 obs. of 3 variables:
$ 총예산 : chr "총수입" "총수입" "총수입" "총수입" ...
$ 세부지출: chr "기타" "복지노인정책과" "예산담당관" "여성가족정책관" ...
$ 예산 : int 2254 1066 1021 710 499 471 358 284 218 198
데이터 유형
> class(data1)
[1] "data.frame"
저장
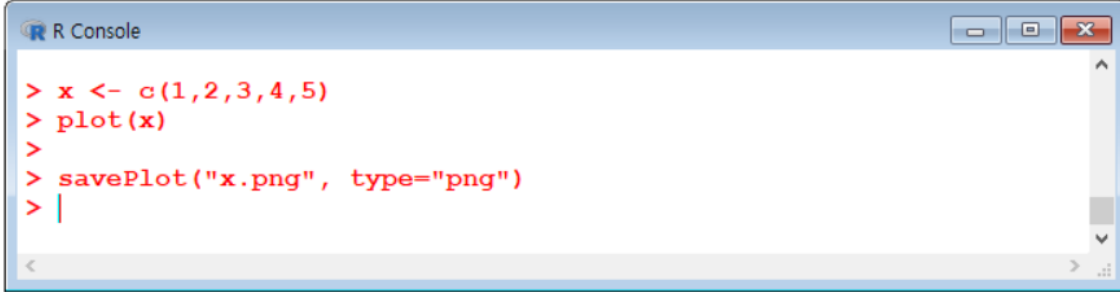
**savePlot() # 그림 저장하기**
plot
x <- c(1,2,3,4)
plot(x) |
 |
 |
|---|
그래프 따로 열기
dev.new()
코드로 열었기 때문에, 그냥 닫으면 안되고, 코드로 닫아야 한다!
savePlot("graph_sale.png", type="png")파일명에만 png를 넣어주는 게 아니라 type에도 넣어줘야 한다.
x <- c(1,2,3,4)
plot(x)
savePlot("graph_sale.png", type="png")
dev.new()순서: plot(x) → dev.new() → 다시 plot(x)에 두고 ctrl+Enter → 그 다음 저장, savePlot → 그 다음 dev.off()
닫기
dev.off()5. 사용자 정의 함수, 조건문, 반복문, 정규식
(1) 사용자 정의 함수

1. 1개의 숫자 입력 받아서 3제곱 값을 출력하는 함수
> myf_1 <- function(a) {
+ b <- a^3
+ return(b)
+ }
> myf_1(3)
[1] 27> myf_1 <- function(a) {
+ return(a^3)
+ }
> myf_1(3)
[1] 27> myf2 <- function(a){
+ print(a^3)
+ }
> myf2(3)
[1] 27> myf3 <-function(a){print(a^3)}
> myf3(3)
[1] 272. 두개의 숫자를 입력 받아서 두 수의 곱을 출력하는 함수 만들기 → 그냥 넘어가셨음
(2) 조건문
조건이 2개만 있는 경우
if (조건)
{
조건에 맞을 때 실행될 식 1
조건에 맞을 때 실행될 식 2
}
else {
조건이 아닐 때 실행될 식1
조건이 아닐 때 실행될 식1
}if~else 예제1: 5 보다 큰 값이 입력되면 1을 출력하고 그 외의 경우는 0을 출력하는 함수
> if_ex1 <- function(x) {
+ if (x > 5){
+ return(1)
+ }
+ else {
+ return(0)
+ }
+ }
> if_ex1(4)
[1] 0
> if_ex1(7)
[1] 1
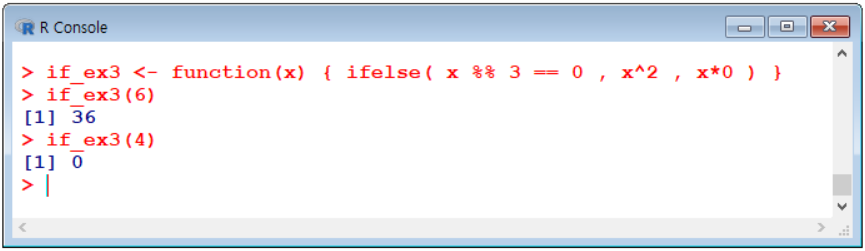
if~else예제2: 입력된 숫자가 3의 배수이면 입력 값의 제곱을 해서 결과를 출력하고 3의 배수가 아닐 경우에는 0 을 출력하는 예제
> if_ex2 <- function(x) {
+ if (x %% 3 == 0){
+ y <- x^2
+ return(y)
+ }
+ else {
+ y <- x*0
+ return(y)
+ }
+ }
> if_ex2(6)
[1] 36
> if_ex1(4)
[1] 0
ifelse 조건문
ifelse(조건, 참일 경우 실행 값, 거짓일 경우 실행 값)
if ~ else if ~ else 문 사용하기 ( 조건이 3개 이상일 경우 )
1. 문법
if ( 조건식 1) {
조건식 1이 참일 때 실행될 문장
}
else if ( 조건식 2) {
조건식 1이 아니고 조건식 2가 참일 경우 실행될 문장
}
…………………
else {
조건식 1도 아니고 조건식 2도 아닐 경우 실행될 문장
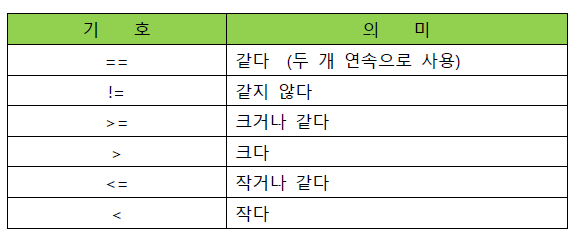
}2. 조건 기호
!=: NOT&,&&: AND|,||: OR
💯If문 Quiz
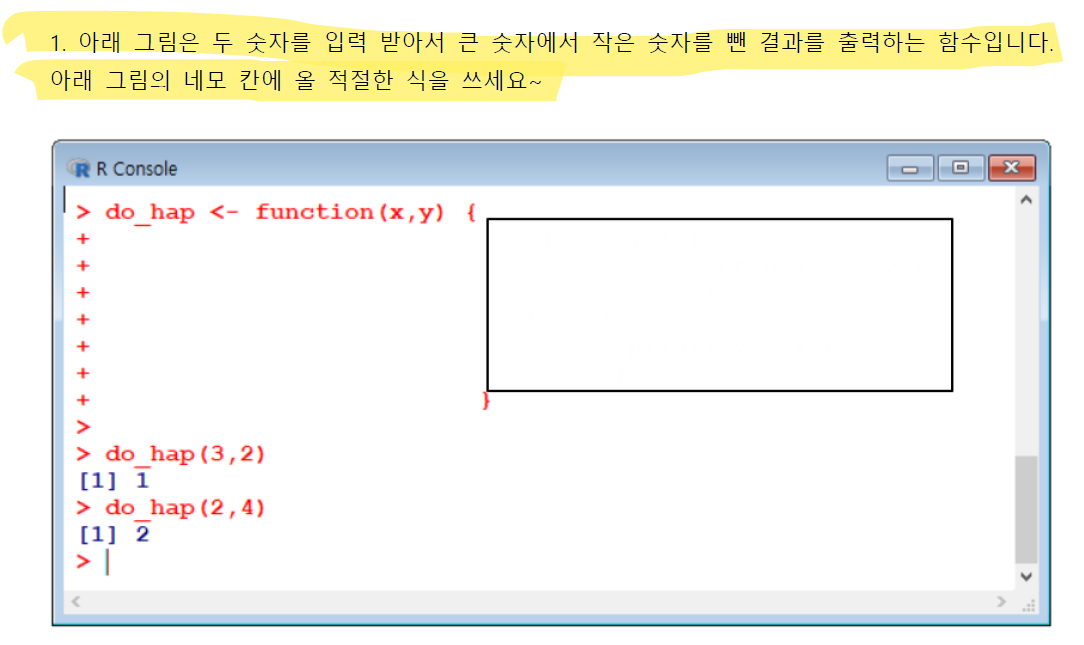
> do_hap <- function(x,y){
+ if (x>y){
+ return(x-y)
+ }
+ else{
+ return(y-x)
+ }
+ }
> do_hap(3,2)
[1] 1
> do_hap(2,4)
[1] 2> do_hap <- function(x,y){
+ if (x>y){print(x-y)}
+ else{print(y-x)}
+ }
> do_hap(3,2)
[1] 1
>
> do_hap(2,4)
[1] 2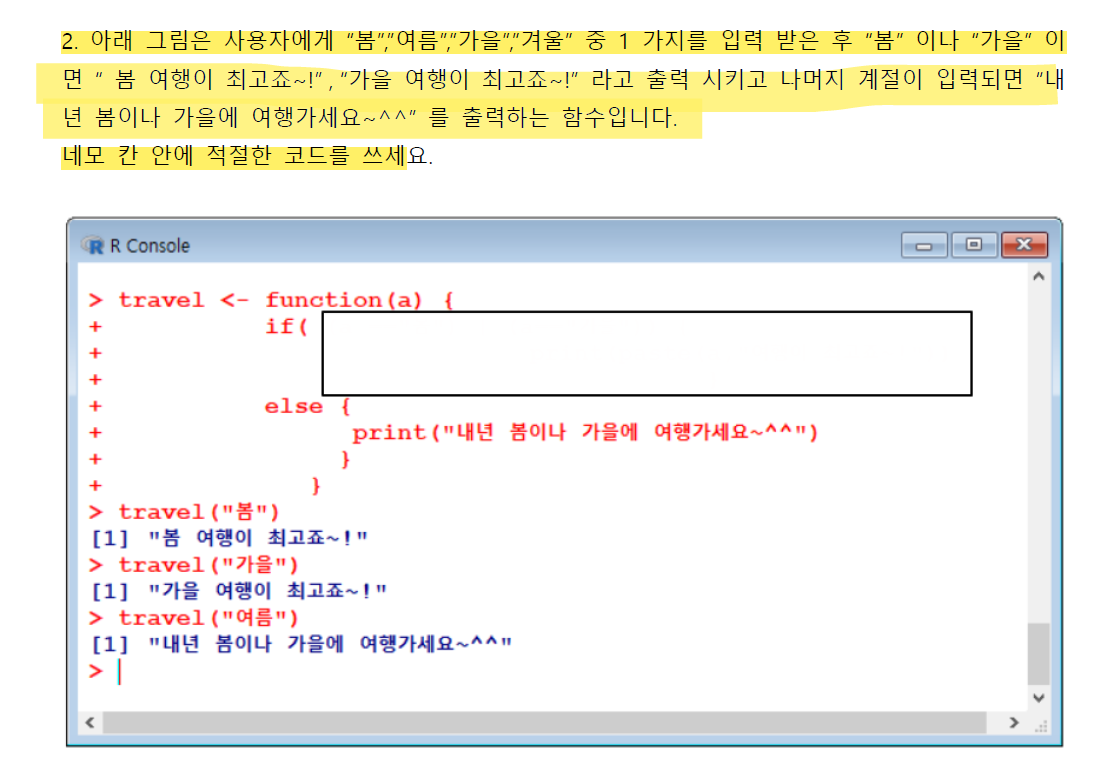
paste 함수
> paste(1, 2, 3)
[1] "1 2 3" # 문자열로 이어짐! 이때 sep의 default값은 공백
> paste("내사람", "꼬깔콘")
[1] "내사람 꼬깔콘"> paste(1, 2, 3, sep = "-")
[1] "1-2-3" # sep이 문자를 이어주는 거를 설정!!#공백없이 출력
> paste(1, 2, 3, sep = "")
[1] "123"
> paste0(1,2,3) # paste0하면 그냥 공백없이 이어짐
[1] "123"travel <- function(a) {
if(a=="봄" | a=="가을"){
print(paste(a, "여행이 최고죠~!"))
}
else{
print("내년 봄이나 가을에 여행가세요~^^")
}
}
travel("봄")
travel("가을")
travel("여름")> travel <- function(a) {
+ if(a=="봄" | a=="가을"){
+ print(paste(a, "여행이 최고죠~!"))
+ }
+ else{
+ print("내년 봄이나 가을에 여행가세요~^^")
+ }
+ }
> travel("봄")
[1] "봄 여행이 최고죠~!"
> travel("가을")
[1] "가을 여행이 최고죠~!"
> travel("여름")
[1] "내년 봄이나 가을에 여행가세요~^^"(3) 반복문
for (i in data){
i를 사용한 문장
}
while(cond) {
조건이 참일 때 수행할 문장
}
repeat {
반복해서 수행할 문장
}
break # 반복문 종료while( ) 반복문 – 조건이 참 일 동안 계속 반복
기본 문법
while(조건) {
실행될 문장 1
실행될 문장 2
조건을 증감하는 문장
}while( ) 반복문 예제 . 숫자를 하나 입력 받아서 1부터 그 숫자까지 화면에 출력하는 예제
> while_ex1 <- function(x){
+ no = 1
+ while(x >= no){
+ print(no)
+ no <- no + 1
+ }
+ }
> while_ex1(4)
[1] 1
[1] 2
[1] 3
[1] 4break / next 활용하기
→ 뒤에 퀴즈에서 활용
- break : 어떤 조건이 나오면 반복을 멈추게 하는 옵션
- next : 특정 조건은 건너 뛰게 만드는 옵션
💯While 퀴즈

charl<-c("새우깡", "맛동산", "자갈치", "칸쵸", "허니버터칩")
charl
cnt <- 0
while(cnt < length(charl)){
cnt <- cnt + 1
if (charl[cnt]=="칸쵸"){
break
}
print(paste("내사랑", charl[cnt]))
}> while(cnt < length(charl)){
+ cnt <- cnt + 1
+ if (charl[cnt]=="칸쵸"){
+ break
+ }
+ print(paste("내사랑", charl[cnt]))
+
+ }
[1] "내사랑 새우깡"
[1] "내사랑 맛동산"
[1] "내사랑 자갈치"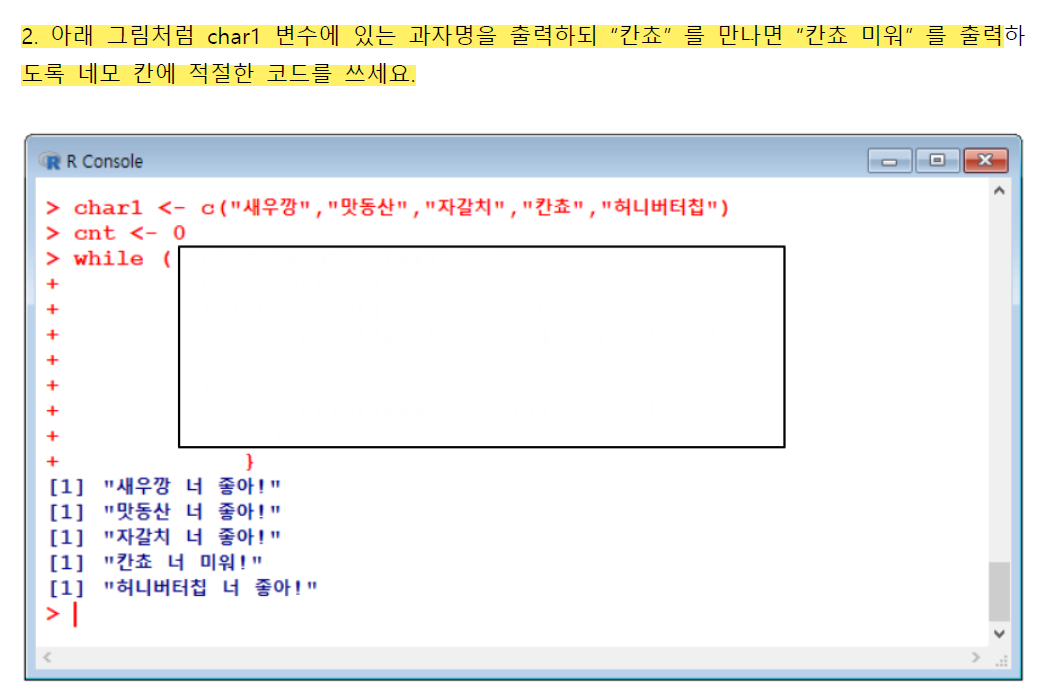
(2) for() 반복문
문법
for ( 변수 in 반복시작숫자 : 반복끝숫자) {
반복할 문장 1
반복할 문장 2
}예제1. 숫자를 하나 입력 받아서 1 부터 해당 숫자까지 연속적인 숫자를 출력
> for(i in 1:4){
+ print(i)
+ }
[1] 1
[1] 2
[1] 3
[1] 4예제2. 숫자를 하나 입력 받아서 1부터 그 숫자까지의 합을 구하는 함수를 for( ) 반복문
> for_ex2 <- function(x) {
+ hap <- 0
+ for (i in 1:x){
+ hap <- hap + i
+ }
+ print(hap)
+ }
> for_ex2(10)
[1] 55
> for_ex2(100)
[1] 5050> cnt <- length(charl)
> cnt
[1] 4
> for(i in 1:cnt){
+ print(charl[i])
+ }
[1] "새우깡"
[1] "맛동산"
[1] "칸쵸"
[1] "허니버터칩"
칸초 안 찍고 무조건 멈출거야 ⇒ break
> for(i in 1:cnt){
+ if(charl[i]=="칸쵸"){
+ break
+ }
+ print(charl[i])
+ }
[1] "새우깡"
[1] "맛동산"
칸쵸만 안 찍고 나머지는 찍고 싶어 ⇒ next
for(i in 1:cnt){
if(charl[i]=="칸쵸"){
next
}
print(charl[i])
}💯for문 퀴즈
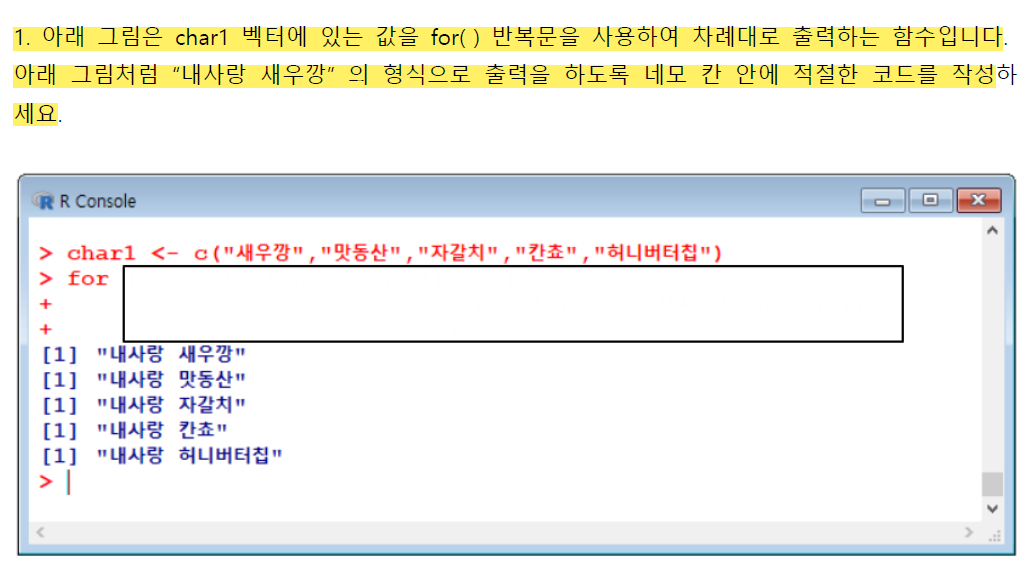
char1 <-c("새우깡", "맛동산", "자갈치", "칸쵸", "허니버터칩")
cnt <- length(char1)
for(i in 1:cnt){
print(paste("내사랑", char1[i]))
}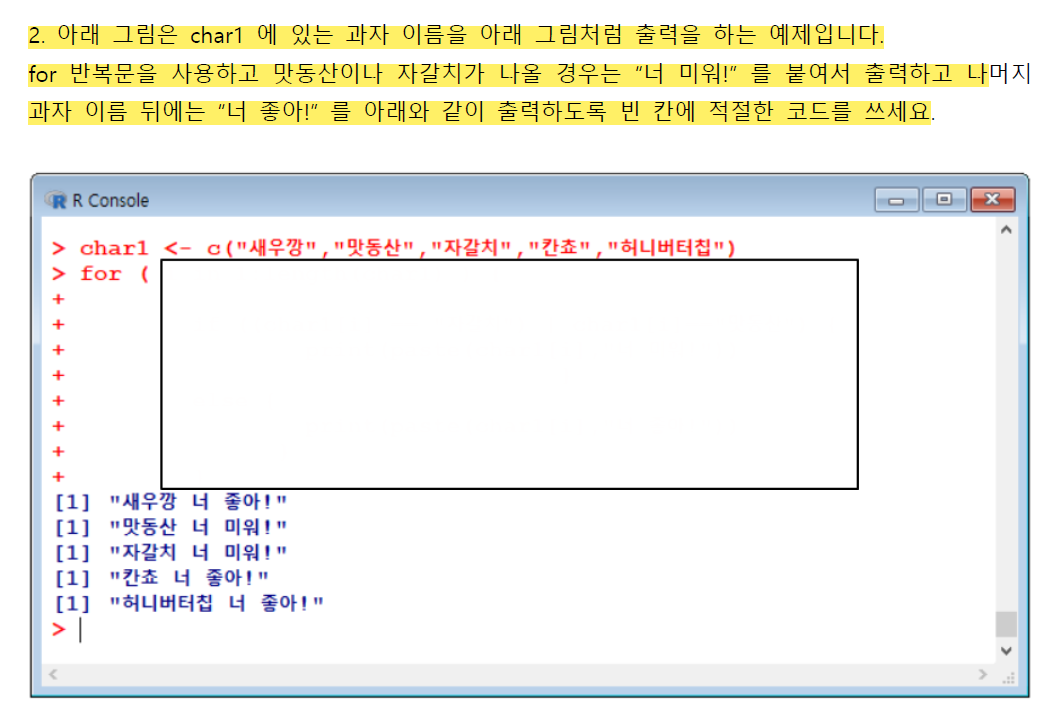
for(i in 1:cnt){
if(char1[i]=="맛동산"|char1[i]=="자갈치"){
print(paste(char1[i], "너 미워!"))
}
else{
print(paste(char1[i], "너 좋아!"))
}
}
gugudan <- function(x){
for(i in 1:9){
print(paste(x,"X",i,"=",x*i))
}
}
gugudan(3)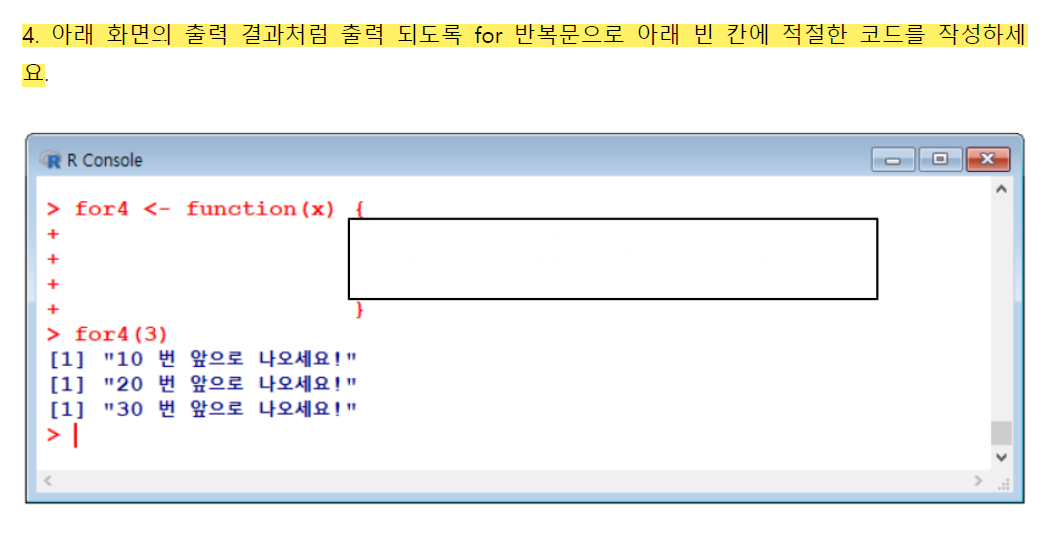
for4 <- function(x){
for(i in 1:x){
print(paste(i*10, "번 앞으로 나오세요!"))
}
}
for4(3)(4) 정규식
주요 정규식 기호와 의미
💡 \\D, \\s, \\W, \\t, ^, $, [ab], [^ab], [A-z]/[a-zA-Z][A-Za-z], i{n, } [:alpha:], [:blank:], [:digit:]
💡 `^`
(예) ^[a] or ^a 첫글자
^ORA : ORA로 시작
^[ORA] : O또는 R또는 A 대괄호 들어가면 또는!
💡 [:digit:] 은 [0-9]와 같은 의미




정규식 주요 함수
- 찾기 :
grep(“ 찾을 내용 ”, data , 옵션 )grep(“ 찾을 내용 ”, data)grep(“ 찾을 내용 ”, data , value=TRUE)값이 아니라 위치값을 찾는다!따라서,value=TRUE를 넣어준다. TRUE 는 꼭 대문자로 해줘야 한다.T로 줄여쓸 수도 있다.> grep("^a", grep_ex, value = TRUE) [1] "a.txt" "ab.txt"- 우리가 필요한 건 위치값이 아니라 데이터가 필요하다.
> grep_ex <- c("a.txt", "A.txt", "ab.txt", "123.txt", "ba123.txt") > grep("^a", grep_ex) [1] 1 3
- 바꾸기
gsub(”변경전글자”. “변경후글자”, data)str_replace_all(data, “변경전글자”, “변경후글자”)
- nchar(”문자열”): 문자열 길이 알려줌
- paste(”문자열1”, “문자열2”, sep=”-” : 여러 단어를 연결해줌
- strsplit(”문자열”. “-”): 특정 기호로 문자 분리
- substr(data, 시작위치, 종료위치): 특정 위치의 문자 잘라줌
- table: 문자열의 빈도수 세는 함수
- sort: 정렬해주는 함수
- sort(data) : 오름차순 정렬, sort(data, descreasing=T): 내림차순 정렬
a로 시작하지 않는 것 : ^[^a]
> grep("^[^a]", grep_ex, value = TRUE)
[1] "A.txt" "123.txt" "ba123.txt"숫자로 시작 ^[0-9]
> grep("^[0-9]", grep_ex, value = TRUE)
[1] "123.txt"숫자로 시작하지 않는 것 ^[^0-9]
> grep("^[^0-9]", grep_ex, value = TRUE)
[1] "a.txt" "A.txt" "ab.txt" "ba123.txt"근데 grep은 하나만 들어갈 수 있다. 따라서 여러 조건이 들어가는 경우, ptn을 만든다.
> paste("^a","|", "^A")
[1] "^a | ^A"
> ptn <- c("^a", "^A")
> paste(ptn, sep="|")
[1] "^a" "^A"> grep(paste(ptn, collapse="|"), grep_ex, value=T)
[1] "a.txt" "A.txt" "ab.txt"nchar: 문자의 길이
> nchar("먹어도 먹어도 배고파요~!")
[1] 14> nchar(grep_ex)
[1] 5 5 6 7 9strsplit: 특정 기호로 문자 분리
> strsplit("031)1234-5678", ")")
[[1]]
[1] "031" "1234-5678"6. R을 활용한 한글/영어 텍스트 분석
(1) 텍스트 처리 기본 사항
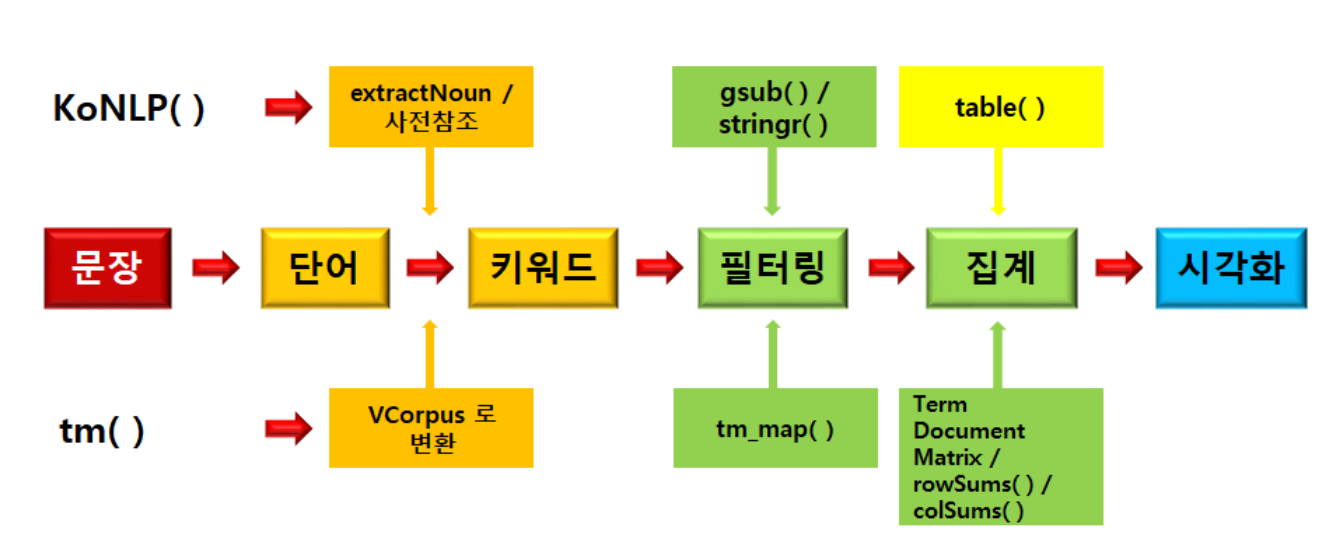
일반적인 텍스트 마이닝 순서
- 패키지:
KoNLP()또는tm()
(2) 한글 텍스트 분석하기
데이터 전처리 작업
사전 활용하기
library(KoNLP)
useSejongDic() # 인터넷을 통해서 업데이트 된 사전을 다운로드 받은 후 사용할 수 있도록 자
동 설정> txt4 <- readLines("좋아하는과일2.txt")
> txt4
[1] "나는 사과와 바나나를 좋아합니다^^ ㅋㅋ."
[2] "나는 바나나 바나나 바나나 바나나 바나나가 최고 좋아요!"
[3] "나는 복숭아와 사과를 좋아합니다ㅎㅎ."
[4] "나는 복숭아와 사과를 좋아합니다ㅎㅎ."
[5] "☎☎☎나는 사과와 바나나를 좋아합니다☎☎☎"
[6] "나는 파인애플과 복숭아를 좋아합니다"
[7] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요!"
[8] "☜☜☜☜나는 망고가 최고 좋아요☜☜☜☜"extractNoun()함수 활용하기 - 한글의 명사 추출 함수
> tx5 <- extractNoun(txt4)
> tx5
[[1]]
[1] "나" "사과" "바나나" "좋아합니다^^"
[[2]]
[1] "나" "바나나" "바나나" "바나나" "바나나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[5]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
[[6]]
[1] "나" "파인애플" "복숭아" "좋아합니"
[[7]]
[1] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[[8]]
[1] "☜☜☜☜나는" "망고" "최고" "좋아요☜☜☜" "☜"> class(tx5)
[1] "list"중복되는 리스트를 제거
> tx6 <-unique(tx5)
> tx6
[[1]]
[1] "나" "사과" "바나나" "좋아합니다^^"
[[2]]
[1] "나" "바나나" "바나나" "바나나" "바나나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
[[5]]
[1] "나" "파인애플" "복숭아" "좋아합니"
[[6]]
[1] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[[7]]
[1] "☜☜☜☜나는" "망고" "최고" "좋아요☜☜☜" "☜"필요 없는 단어 제거하기 – 특정 단어나 글자수로 제거하기
> #list안에서 하나하나 비교
> tx7 <- lapply(tx6, unique)
> tx7
[[1]]
[1] "나" "사과" "바나나" "좋아합니다^^"
[[2]]
[1] "나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
[[5]]
[1] "나" "파인애플" "복숭아" "좋아합니"
[[6]]
[1] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[[7]]
[1] "☜☜☜☜나는" "망고" "최고" "좋아요☜☜☜" "☜"> #낱개
> tx8<-unlist(tx7)
> tx8
[1] "나"
[2] "사과"
[3] "바나나"
[4] "좋아합니다^^"
[5] "나"
[6] "바나나"
[7] "최고"
[8] "나"
[9] "복숭아"
[10] "사과"
[11] "좋아합니다^ㅎ^ㅎ"
[12] "☎☎☎나는"
[13] "사과"
[14] "바나나"
[15] "좋아합니다☎☎"
[16] "☎"
[17] "나"
[18] "파인애플"
[19] "복숭아"
[20] "좋아합니"
[21] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[22] "☜☜☜☜나는"
[23] "망고"
[24] "최고"
[25] "좋아요☜☜☜"
[26] "☜"특정 글자 없애기 : gsub 사용
문법 : gsub(“변경전글자” , ”변경후글자” , data)
> #문자가 아닌 것 제외
> # 대괄호 안쪽: 아닌 것 / 바깥쪽: 시작하는것
> # 또는 하고 싶으니까 큰 대괄호 넣음
> tx9<-gsub("[^[:alpha:][:blank:]]", "", tx8)
> tx9
[1] "나"
[2] "사과"
[3] "바나나"
[4] "좋아합니다"
[5] "나"
[6] "바나나"
[7] "최고"
[8] "나"
[9] "복숭아"
[10] "사과"
[11] "좋아합니다ㅎㅎ"
[12] "나는"
[13] "사과"
[14] "바나나"
[15] "좋아합니다"
[16] ""
[17] "나"
[18] "파인애플"
[19] "복숭아"
[20] "좋아합니"
[21] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[22] "나는"
[23] "망고"
[24] "최고"
[25] "좋아요"
[26] ""> txt10 <- Filter(function(x){nchar(x)>= 2 & nchar(x)<10}, tx9)
> txt10
[1] "사과" "바나나" "좋아합니다" "바나나"
[5] "최고" "복숭아" "사과" "좋아합니다ㅎㅎ"
[9] "나는" "사과" "바나나" "좋아합니다"
[13] "파인애플" "복숭아" "좋아합니" "나는"
[17] "망고" "최고" "좋아요"> txt11 <- gsub("최고", "", txt10)
> txt11
[1] "사과" "바나나" "좋아합니다" "바나나"
[5] "" "복숭아" "사과" "좋아합니다ㅎㅎ"
[9] "나는" "사과" "바나나" "좋아합니다"
[13] "파인애플" "복숭아" "좋아합니" "나는"
[17] "망고" "" "좋아요"> g_txt <- readLines("friuits_g.txt")
Warning message:
In readLines("friuits_g.txt") :
incomplete final line found on 'friuits_g.txt'
> g_txt
[1] "좋아합니다" "좋아합니" "좋아요" "나는" "ㅎㅎ"
> for(i in 1:length(g_txt)){
+ txt11 <- gsub(g_txt[i],"", txt11)
+ }
> txt11
[1] "사과" "바나나" "" "바나나" "" "복숭아" "사과"
[8] "" "" "사과" "바나나" "" "파인애플" "복숭아"
[15] "" "" "망고" "" ""> txt12 <- Filter(function(x){nchar(x)>1 & nchar(x)<=10}, txt11)
> txt12
[1] "사과" "바나나" "바나나" "복숭아" "사과" "사과" "바나나"
[8] "파인애플" "복숭아" "망고"정제 끝!
word!!
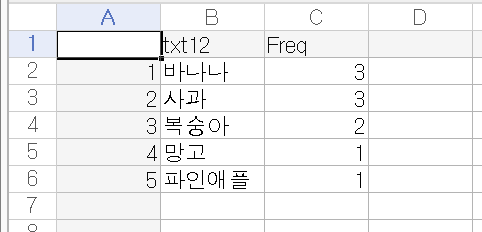
> word_cnt <- table(txt12)
> word_cnt
txt12
망고 바나나 복숭아 사과 파인애플
1 3 2 3 1
> sort(word_cnt, decreasing = T)
txt12
바나나 사과 복숭아 망고 파인애플
3 3 2 1 1저장하기
> 과일_cnt <- sort(word_cnt, decreasing = T)
> write.csv(과일_cnt, "과일.csv")
결과

wordcloud
word_cnt <- table(txt12)
word_cnt
과일_cnt <- sort(word_cnt, decreasing = T)
write.csv(과일_cnt, "과일.csv")
install.packages("wordcloud")
library(wordcloud)
pal <- brewer.pal(8, "Set3") # 팔레트에 색상 지정
# 밑에 wordcloud는 다 똑같음 밑에 names(word_cnt)부분, freguency부분만 수정하면 됨
wordcloud(names(word_cnt), freq=word_cnt, scale=c(4,0.5),
min.freq=0.5, rot.per = 0.5, random.order = F,
random.color = T, colors=pal)> word_cnt <- table(txt12)
> word_cnt
txt12
망고 바나나 복숭아 사과 파인애플
1 3 2 3 1
> 과일_cnt <- sort(word_cnt, decreasing = T)
> write.csv(과일_cnt, "과일.csv")
> install.packages("wordcloud")
Error in install.packages : Updating loaded packages
Restarting R session...
> install.packages("wordcloud")
‘C:/Users/rlaal/Documents/R/win-library/4.1’의 위치에 패키지(들)을 설치합니다.
(왜냐하면 ‘lib’가 지정되지 않았기 때문입니다)
trying URL 'https://cran.rstudio.com/bin/windows/contrib/4.1/wordcloud_2.6.zip'
Content type 'application/zip' length 782413 bytes (764 KB)
downloaded 764 KB
package ‘wordcloud’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\rlaal\AppData\Local\Temp\RtmpQx4pS0\downloaded_packages
> library(wordcloud)
필요한 패키지를 로딩중입니다: RColorBrewer
> pal <- brewer.pal(8, "Set3") # 팔레트에 색상 지정
> # 밑에 wordcloud는 다 똑같음 밑에 names(word_cnt)부분, freguency부분만 수정하면 됨
> wordcloud(names(word_cnt), freq=word_cnt, scale=c(4,0.5),
+ min.freq=0.5, rot.per = 0.5, random.order = F,
+ random.color = T, colors=pal)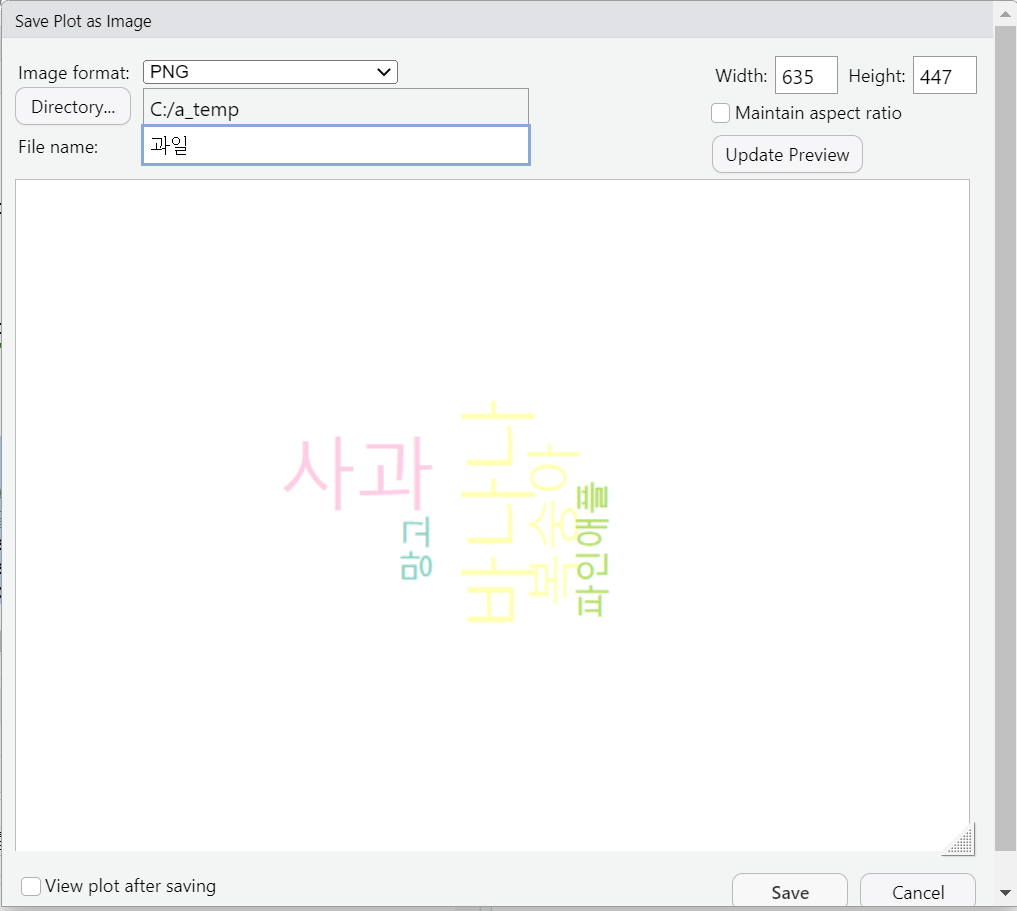

→ wargning 메시지는 상관없음!~
[예제] 경주 여행지 추천 키워드 분석하기
원본파일 / 클라우드 결과


소스코드
##############################################################
## 예제 1. 경주 여행지 추천 소스코드<교재5_P13>
##############################################################
# KoNLP 패키지로 한글 분석하는 종합 정리 #
#Step 1. 작업디렉토리 설정하고 필요한 패키지를 설치 및 구동
setwd("c:\\temp\\")
install.packages("KoNLP")
install.packages("wordcloud")
install.packages("stringr")
library(stringr)
library(KoNLP)
library(wordcloud)
useSejongDic()
data1 <- readLines("경주여행_지식인_2016.txt", encoding="UTF-8")
head(data1,10)
length(data1)
data1 <- unique(data1)
data2 <- str_replace_all(data1,"[^[:alpha:][:digit:]]"," ")
data3 <- extractNoun(data2)
head(data3,5)
data4 <- lapply(data3, unique) # 각 리스트안에서 중복된 단어들 제거하기
data5 <- gsub("\\d+", "", unlist(data4))
data5 <- gsub("스프링", "스프링돔", data5)
data5 <- gsub("파크", "워터파크", data5)
data5 <- gsub("\\^", "", data5)
data5 <- gsub(paste(c("교촌","마을","한옥"),collapse='|'), "교촌한옥마을", data5)
data5 <- gsub(paste(c("주상","절리"),collapse='|'), "주상절리", data5)
data5 <- gsub(paste(c("보문단지","보문"),collapse='|'), "보문관광단지", data5)
data5 <- gsub(paste(c("달동네","추억","추억의달동네"),collapse='|'), "추억의달동네", data5)
data5 <- gsub(paste(c("한우","떡갈비"),collapse='|'), "한우수제떡갈비", data5)
data5 <- gsub(paste(c("게스트","하우스"),collapse='|'), "게스트하우스", data5)
data5 <- gsub(paste(c("월성","반월성"),collapse='|'), "반월성", data5)
data5 <- gsub(paste(c("맛집이","맛집"),collapse='|'), "맛집", data5)
data5 <- gsub(paste(c("교리","김밥","계란지단"),collapse='|'), "교리김밥", data5)
data5 <- gsub(paste(c("천마","천마총"),collapse='|'), "천마총", data5)
data5 <- gsub(paste(c("박물관","테디베어","테디베어박물관"),collapse='|'), "테디베어박물관", data5)
data5 <- gsub("월드", "월드엑스포", data5)
data5 <- gsub("순두부", "멧돌순두부", data5)
data5 <- gsub(paste(c("현대","밀면"),collapse='|'), "현대밀면", data5)
data5 <- gsub("한정", "이조한정식", data5)
data5 <- gsub("블루", "블루원워터파크",data5)
data5 <- lapply(data5, unique) # 각 리스트안에서 중복된 단어들 제거하기
# 글자수로 제거하기, 2글자 이상 6글자 이하만 출력
data6 <- sapply(data5, function(x) {Filter(function(y) {nchar(y) <= 6 && nchar(y) > 1 },x)} )
wordcount <- table(unlist(data6))
wordcount <- Filter(function(x) {nchar(x) <= 10} ,wordcount)
head(sort(wordcount, decreasing=T),100)
txt <- readLines("경주gsub.txt")
txt
cnt_txt <- length(txt)
cnt_txt
for( i in 1:cnt_txt) {
data5 <- gsub((txt[i]),"", data5)
}
head(data5,5)
data6 <- sapply(data5, function(x) {Filter(function(y) { nchar(y) >=2 },x)} )
head(data6,5)
#아래 과정이 필터링이 완료된 단어들을 언급 빈도수로 집계하는 과정입니다.
wordcount <- table(unlist(data6))
head(sort(wordcount, decreasing=T),100)
library(RColorBrewer)
palete <- brewer.pal(7,"Set2")
wordcloud(names(wordcount),freq=wordcount,scale=c(5,1),rot.per=0.25,min.freq=28,
random.order=F,random.color=T,colors=palete)
# Step 8- 언급된 빈도에 따라 색깔을 다르게 설정하기
wordcount <- table(unlist(data6))
data54 <- head(sort(wordcount , decreasing=T) , 100)
# write.table 과 read.table 에 대한 내용은 이 책 Chap 의 페이지 를 참고하세요~
write.table(data54,"data54.txt")
data64 <- read.table("data54.txt")
# 언급 빈도에 따라 색깔을 다르게 설정함
# 예제는 100번 이상 언급된 키워드는 빨간색으로 표시하고 나머지는 회색으로 표시하여 강조함
col4 <- ifelse(data64$Freq >= 100 , "red" , "gray") # ifelse 문장은 반복문 부분을 참고하세요~
wordcloud(data64$Var1 , freq=data64$Freq , scale=c(4,1) , rot.per=0.25 , min.freq=1 ,
random.order=F , ordered.color=T , colors=col4 )
# wordcloud2( ) 패키지로 시각화 하기
install.packages("wordcloud2")
library(wordcloud2)
wordcount2 <- head(sort(wordcount, decreasing=T),100)
wordcloud2(wordcount2,gridSize=1,size=0.5,shape="polygon")
# shape = “diamond” , “star” , “circle” 등 다양한 옵션 사용 가능함.Step 1. 작업 디렉토리 설정하고 필요 패키지 설치 및 실행하기
> setwd("c:\\temp\\")
> install.packages("KoNLP")
> install.packages("wordcloud")
> install.packages("stringr")
>
> library(stringr)
> library(KoNLP)
> library(wordcloud)
>
> useSejongDic()Step 2. 분석할 파일 불러오기
> data1 <- readLines("경주여행_지식인_2016.txt", encoding="UTF-8")
> head(data1,10) # 잘 불러졌는지 앞부분의 10줄만 보고 확인하기
> length(data1) # 분석해야 할 텍스트가 총 몇 줄인지 확인Step 3. 중복값 제거하고 필요 없는 특수문자 제거한 후 명사만 추출하기
> data1 <- unique(data1)
> data2 <- str_replace_all(data1,"[^[:alpha:][:digit:]]"," ")
> data3 <- extractNoun(data2)
> head(data3,5)
[[1]]
[1] " "
[[2]]
[1] "제목" "경주" "여행" "문의" "드" "5"
[[3]]
[1] "날짜" "질문마감률70" "5"
[[4]]
[1] "질문" "내용" "안녕" "겨울" "아이들"
[6] "경주" "여행" "준비" "2" "박"
[11] "혹은3박" "정도" "계획" "중" "유적지"
[16] "외" "만" "곳" "아이들" "물놀이"
[21] "경주" "호텔" "리조트" "중아이들이" "수"
[26] "실내" "워터" "파크" "곳" "어디인지요"
[31] "들" "추천" "부탁드립니"
[[5]]
[1] "답변"
[2] "안녕"
[3] "여행"
[4] "블로거"
... 밑에 일부 생략Step 4. 불용어 제거 및 용어 정리하기
> data4 <- lapply(data3, unique) # 각 리스트안에서 중복된 단어들 제거하기
> data5 <- gsub("\\d+", "", unlist(data4)) #숫자데이터 지워짐
> head(data5, 20)
[1] " "
[2] "제목"
[3] "경주"
[4] "여행"
[5] "문의"
[6] "드"
[7] ""
[8] "날짜"
[9] "질문마감률"
[10] ""
[11] "질문"
[12] "내용"
[13] "안녕"
[14] "겨울"
[15] "아이들"
[16] "경주"
[17] "여행"
[18] "준비"
[19] ""
[20] "박"> data5 <- gsub("스프링", "스프링돔", data5)
> data5 <- gsub("파크", "워터파크", data5)
> data5 <- gsub("\\^", "", data5)
> data5 <- gsub(paste(c("교촌","마을","한옥"), collapse='|'), "교촌한옥마을", data5)
> data5 <- gsub(paste(c("주상","절리"), collapse='|'), "주상절리", data5)
> data5 <- gsub(paste(c("보문단지","보문"), collapse='|'), "보문관광단지", data5)
> data5 <- gsub(paste(c("달동네","추억","추억의달동네"), collapse='|'), "추억의달동네", data5)
> data5 <- gsub(paste(c("한우","떡갈비"), collapse='|'), "한우수제떡갈비", data5)
> data5 <- gsub(paste(c("게스트","하우스"), collapse='|'), "게스트하우스", data5)>data5 <- gsub(paste(c("월성","반월성"), collapse='|'), "반월성", data5)
> data5 <- gsub(paste(c("맛집이","맛집"), collapse='|'), "맛집", data5)
> data5 <- gsub(paste(c("교리","김밥","계란지단"), collapse='|'), "교리김밥", data5)
> data5 <- gsub(paste(c("천마","천마총"), collapse='|'), "천마총", data5)
> data5 <- gsub(paste(c("박물관","테디베어","테디베어박물관"), collapse='|'), "테디베어박물관",
data5)
> data5 <- gsub("월드", "월드엑스포", data5)
> data5 <- gsub("순두부", "멧돌순두부", data5)
> data5 <- gsub(paste(c("현대","밀면"), collapse='|'), "현대밀면", data5)
> data5 <- gsub("한정", "이조한정식", data5)
> data5 <- gsub("블루", "블루원워터파크",data5)\
>
> data5 <- lapply(data5, unique) # 각 리스트안에서 중복된 단어들 제거하기
>
> data6 <- sapply(data5, function(x) {Filter(function(y) {nchar(y) <= 6 & nchar(y) > 1 } , x ) } ) # 글자수로 제거하기, 2글자 이상 6글자 이하만 출력data5 : 파크를 워터파크로 바꿔라!, 스프링을 스프링돔으로 바꿔라. \^는 뭐더라!
> data6 <- sapply(data5, function(x) {Filter(function(y) {nchar(y) <= 6 && nchar(y) > 1 },x)} )
> head(data6, 20)
[[1]]
character(0)
[[2]]
[1] "제목"
[[3]]
[1] "경주"
[[4]]
[1] "여행"
[[5]]
[1] "문의"
[[6]]
character(0)
[[7]]
character(0)
[[8]]
[1] "날짜"
[[9]]
[1] "질문마감률"
[[10]]
character(0)
[[11]]
[1] "질문"
[[12]]
[1] "내용"
[[13]]
[1] "안녕"
[[14]]
[1] "겨울"
[[15]]
[1] "아이들"
[[16]]
[1] "경주"
[[17]]
[1] "여행"
[[18]]
[1] "준비"
[[19]]
character(0)
[[20]]
character(0)Step 5. 추출된 명사들을 집계하여 현황 보기 – 추가적인 불용어 제거 작업 위해서 수행
> wordcount <- table(unlist(data6))
> wordcount <- Filter(function(x) {nchar(x) <= 10} ,wordcount)
> head(sort(wordcount, decreasing=T),100) #내림차순으로 sort
경주 여행 답변 질문 내용
488 338 303 242 210
제목 교촌한옥마을 추천 코스 추억의달동네
205 188 161 146 140
맛집 안압지 첨성대 유명 날짜
119 112 94 92 91
게스트하우스 불국사 주상절리 정도 질문마감률
90 90 90 88 83
경주맛집 보문관광단지 생각 하시 안녕
80 80 80 80 78
근처 해서 교리김밥 박일 하게
77 75 74 70 70
가격 음식 들이 반월성 가족
69 67 66 65 63
숙소 야경 현대밀면 버스 저렴
63 63 61 59 59
친구 대릉 시간 경주시 이조한정식
59 58 58 57 57
사람 터미널 동궁 석굴암 숙박
56 56 54 54 54
주변 정보 호텔 때문 식사
54 53 53 52 52
저희 다양 경주로 경주역 천마총
50 49 48 48 47
가능 볼거리 이곳 한곳 거리
45 43 43 43 41
도움 이용 체험 검색 참고
41 41 41 40 40
푸짐 등등 리조트 하루 구경
40 39 39 39 38
이동 일정 장소 그곳 문화
38 38 38 37 37
깔끔 대부분 먹거리 식당 위치
36 36 36 36 36
엑스포 국물 멧돌순두부 방문 월지
35 34 34 34 34
고급 많이들 어디 인기 저녁
33 33 33 33 33
풍경 국립 만족 입구 전문
33 32 32 32 32⇒ 장소를 남겨야 하기 때문에 장소 빼고 나머지는 지워야 한다.
Step 6. 추가로 확인된 불용어를 다시 제거하기
불용어들을 파일에 저장한 후 불러와서 제거하는 방식 사용
kyungju_g.txt
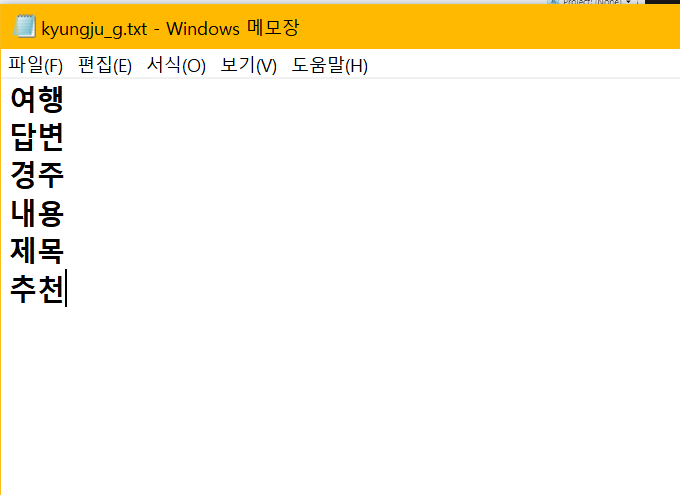
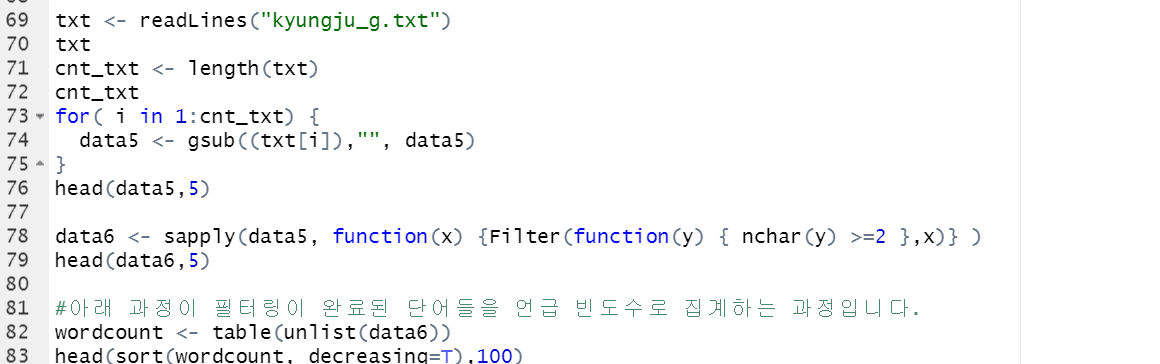
> txt <- readLines("kyungju_g.txt")
> txt
[1] "여행" "답변" "경주" "내용" "제목" "추천"
> cnt_txt <- length(txt)
> cnt_txt
[1] 6
> for( i in 1:cnt_txt) {
+ data5 <- gsub((txt[i]),"", data5)
+ }
> head(data5,5)
[1] " "
[2] ""
[3] ""
[4] ""
[5] "문의"sapply 사용
> data6 <- sapply(data5, function(x) {Filter(function(y) { nchar(y) >=2 },x)} )
> head(data6,5)> data6 <- sapply(data5, function(x) {Filter(function(y) { nchar(y) >=2 },x)} )
> head(data6,5)
$` `
[1] " "
[[2]]
character(0)
[[3]]
character(0)
[[4]]
character(0)
$문의
[1] "문의"다시 wordcloud로 확인! why? 키워드가 아닌 게 또 들어갔는지 아닌지 확인하기 위해서!
> wordcount <- table(unlist(data6))
> head(sort(wordcount, decreasing=T),100)
질문 맛집 교촌한옥마을
242 203 188
코스 한우수제떡갈비 추억의달동네
153 145 140
테디베어박물관 안압지 첨성대
127 112 94
유명 날짜 게스트하우스
92 91 90
불국사 주상절리 정도
90 90 88
보문관광단지 질문마감률 생각
85 83 80
하시 안녕 근처
80 78 77
해서 교리김밥 박일
75 74 72
하게 가격 음식
70 69 67
들이 반월성 가족
66 65 63
숙소 야경 현대밀면
63 63 61
버스 저렴 친구
59 59 59
대릉 시간 월드엑스포
58 58 58
이조한정식 사람 터미널
57 56 56
동궁 석굴암 숙박
54 54 54
주변 버드워터파크 정보
54 53 53
호텔 때문 식사
53 52 52
저희 다양 천마총
50 49 47
가능 볼거리 이곳
45 43 43
한곳 거리 도움
43 41 41
이용 체험 검색
41 41 40
참고 푸짐 등등
40 40 39
리조트 하루 구경
39 39 38
이동 일정 장소
38 38 38
그곳 문화 깔끔
37 37 36
대부분 먹거리 시내
36 36 36
식당 위치 보문관광단지관광단지
36 36 35
엑스포 국물 멧돌순두부
35 34 34
방문 월지 고급
34 34 33
많이들 어디 인기
33 33 33
저녁 풍경 국립
33 33 32
만족 맛집입니다 신라밀레니엄워터파크
32 32 32
입구 전문 하기
32 32 32
예약
31키워드 아닌 게 또 들어옴…
나중에 일할 때는 깔끔하게 확인해야 함..
키워드 아닌 게 나왔으면 다시 txt파일 수정해서 아래 부분의 코드를 다시 수행
수정해보았다.
결과
질문 맛집 교촌한옥마을 코스
242 203 188 153
한우수제떡갈비 추억의달동네 테디베어박물관 안압지
145 140 127 112
첨성대 게스트하우스 불국사 주상절리
94 90 90 90
정도 보문관광단지 질문마감률 생각
88 85 83 80
근처 교리김밥 음식 들이
77 74 67 66
반월성 숙소 야경 현대밀면
65 63 63 61
버스 대릉 월드엑스포 이조한정식
59 58 58 57
터미널 동궁 석굴암 숙박
56 54 54 54
주변 버드워터파크 호텔 천마총
54 53 53 47
리조트 보문관광단지관광단지 시내 식당
39 36 36 36
엑스포 멧돌순두부 방문 월지
35 34 34 34
고급 풍경 국립 만족
33 33 32 32
벚꽃 신라밀레니엄워터파크 이번 입맛
32 32 31 31
전통 계획 반찬 소요
31 30 30 30
적당 중간 관광지 담백
30 30 29 29
대중교통 동해 부모님 요리
29 29 29 29
우리 황남빵 김유신장군묘 동천
29 29 28 28
블루원워터파크 얼마 왕릉 자랑
28 28 28 28
자전거 정식 제공 중심
28 28 28 28
무난 삼릉 센터 순서
27 27 27 27
콘도 파도소리 개운 관광
27 27 26 26
남산 대전 대표적 반나절
26 26 26 26
보문관광단지동 봉길해수욕장 북군동 분황사
26 26 26 26
시대 시원 시장 여기
26 26 26 26
이름 인왕 칼국수 펜션
26 26 26 26또 수정해서 112개로 걸렀는데
> head(sort(wordcount, decreasing=T),100)
맛집 교촌한옥마을 한우수제떡갈비
211 188 145
추억의달동네 테디베어박물관 안압지
140 127 112
첨성대 게스트하우스 불국사
94 90 90
주상절리 보문관광단지 마감률
90 88 83
교리김밥 반월성 현대밀면
74 66 61
대릉 월드엑스포 이조한
58 58 57
동궁 석굴암 버드워터파크
54 54 53
관광 펜션 천마총
52 51 47
리조트 보문관광단지관광단지 시내
39 36 36
엑스포 멧돌순두부 월지
35 34 34
풍경 국립 벚꽃
33 32 32
신라밀레니엄워터파크 전통 동해
32 31 29
황남빵 김유신장군묘 동천
29 28 28
블루원워터파크 왕릉 무난
28 28 27
삼릉 시외 콘도
27 27 27
파도소리 개운 남산
27 26 26
대전 보문관광단지동 봉길해수욕장
26 26 26
북군동 분황사 시장
26 26 26
인왕 주요 칼국수
26 26 26
핫한 감포읍 감포항
26 25 25
건천 계란지 근대사
25 25 25
날씨 남쪽 노동
25 25 25
모델 보문관광단지관광단지에는 보물
25 25 25
석탑 소개 신선
25 25 25
안강 여왕 요석궁
25 25 25
우엉 월정교 인정
25 25 25
장모 전국 정리
25 25 25
조선 중부 중앙시장
25 25 25
트래킹 포항 홍아교리김밥
25 25 25
황오동 가끔가는 감포일출복어
25 24 24
감포일출복어는 감포쪽으로 경애왕릉포석정용장계곡곰바위칠불암
24 24 24
고택 교동 교리김밥맛집
24 24 24
교리김밥인데요 교수 교수님
24 24 24
기호
24
>한번더! (실기 때는 이렇게까지 안해도 됨)
맛집 교촌한옥마을
211 188
한우수제떡갈비 추억의달동네
145 140
테디베어박물관 안압지
127 112
첨성대 게스트하우스
94 90
불국사 주상절리
90 90
보문관광단지 마감률
88 83
교리김밥 반월성
74 66
현대밀면 대릉
61 58
월드엑스포 이조한
58 57
동궁 석굴암
54 54
버드워터파크 관광
53 52
펜션 천마총
51 47
리조트 보문관광단지관광단지
39 36
시내 엑스포
36 35
멧돌순두부 월지
34 34
풍경 국립
33 32
벚꽃 신라밀레니엄워터파크
32 32
전통 동해
31 29
황남빵 김유신장군묘
29 28
동천 블루원워터파크
28 28
왕릉 무난
28 27
삼릉 시외
27 27
콘도 파도소리
27 27
개운 남산
26 26
대전 보문관광단지동
26 26
봉길해수욕장 북군동
26 26
분황사 시장
26 26
인왕 주요
26 26
칼국수 핫한
26 26
감포읍 감포항
25 25
건천 계란지
25 25
근대사 날씨
25 25
남쪽 노동
25 25
모델 보문관광단지관광단지에는
25 25
보물 석탑
25 25
소개 신선
25 25
안강 여왕
25 25
요석궁 우엉
25 25
월정교 인정
25 25
장모 전국
25 25
정리 조선
25 25
중부 중앙시장
25 25
트래킹 포항
25 25
홍아교리김밥 황오동
25 25
가끔가는 감포일출복어
24 24
감포일출복어는 감포쪽으로
24 24
경애왕릉포석정용장계곡곰바위칠불암 고택
24 24
교동 교리김밥맛집
24 24
교리김밥인데요 교수
24 24
교수님 기호
24 24이 과정을 반복하며 데이터 정제시킨다.
Step 7. 워드 클라우드로 시각화 하기
이제 wordcloud하기!
> library(RColorBrewer)
> palete <- brewer.pal(7,"Set2")
> wordcloud(names(wordcount),freq=wordcount,scale=c(4,0.5),rot.per=0.25,min.freq=28,
random.order=F,random.color=T,colors=palete)
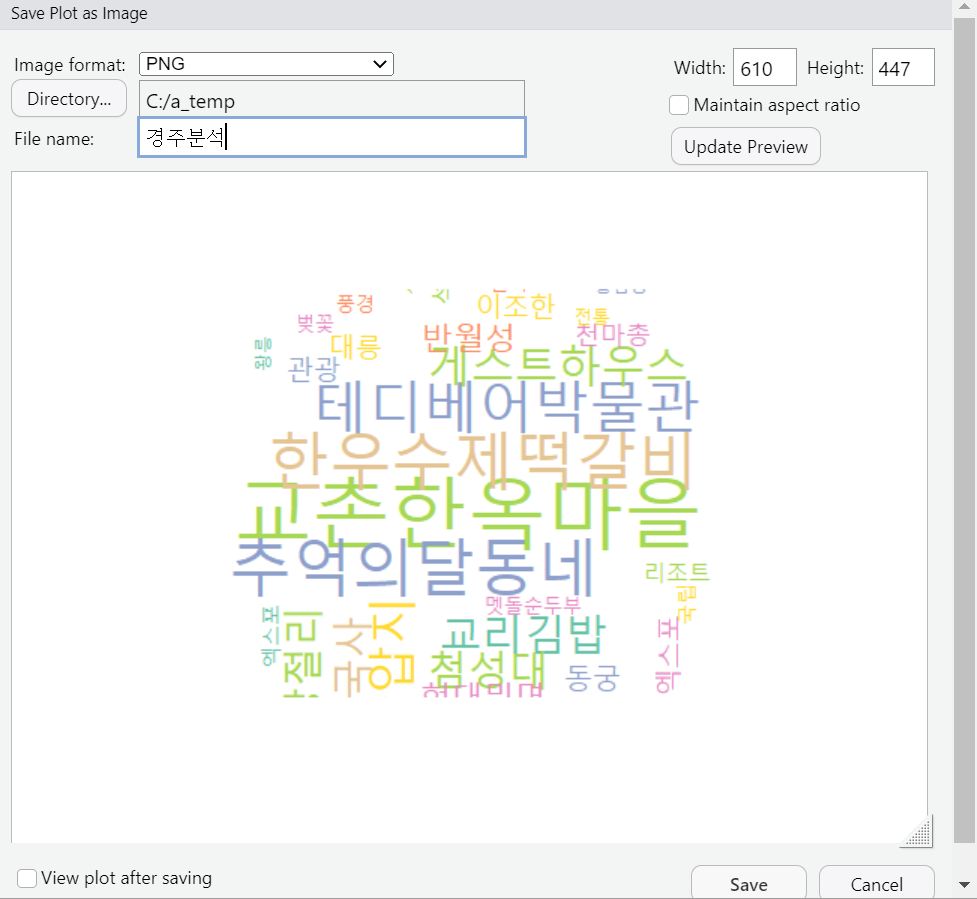
dev.new()를 이용하면 창에서 나옴
dev.new()
dev.off()Step 8- 언급된 빈도에 따라 색깔을 다르게 설정하기
100회 이상 → 빨간색, 나머지 → 그레이 (if문 이용)
# write.table 과 read.table 에 대한 내용은 이 책 Chap 의 페이지 를 참고하세요~
write.table(data54,"data54.txt")
data64 <- read.table("data54.txt")
# 언급 빈도에 따라 색깔을 다르게 설정함
# 예제는 100번 이상 언급된 키워드는 빨간색으로 표시하고 나머지는 회색으로 표시하여 강조함
col4 <- ifelse(data64$Freq >= 100 , "red" , "gray") # ifelse 문장은 반복문 부분을 참고하세요~
wordcloud(data64$Var1 , freq=data64$Freq , scale=c(4,0.5) , rot.per=0.25 , min.freq=1 ,
random.order=F , ordered.color=T , colors=col4 )> head(data64,10)
Var1 Freq
1 교촌한옥마을 188
2 한우수제떡갈비 152
3 추억의달동네 142
4 테디베어박물관 127
5 안압지 112
6 교리김밥 98
7 불국사 94
8 첨성대 94
9 보문관광단지 93
10 게스트하우스 90> head(data64$Var1)
[1] "교촌한옥마을" "한우수제떡갈비" "추억의달동네"
[4] "테디베어박물관" "안압지" "교리김밥"
Step 8. wordcloud2 ( ) 패키지로 시각화 하기
wordcloud2
# wordcloud2( ) 패키지로 시각화 하기
install.packages("wordcloud2")
library(wordcloud2)
wordcount2 <- head(sort(wordcount, decreasing=T),100)
wordcloud2(wordcount2,gridSize=1,size=0.5,shape="polygon")- shape = “diamond” , “star” , “circle” 등 다양한 옵션 사용 가능함.
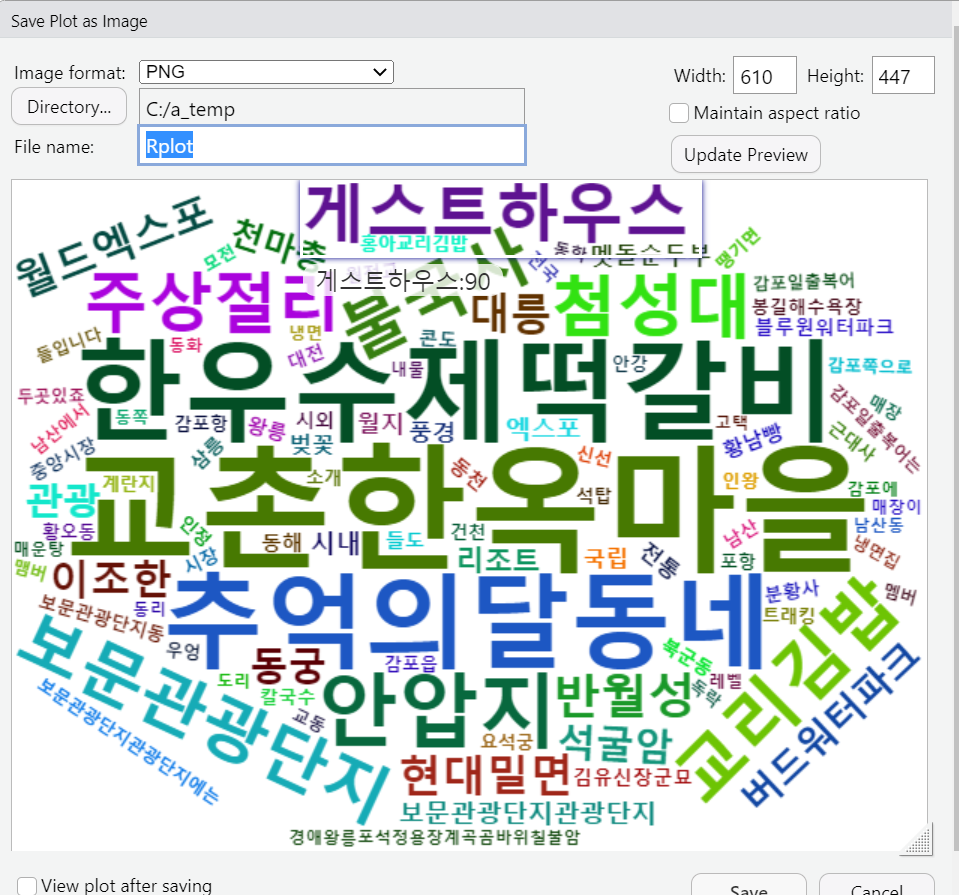
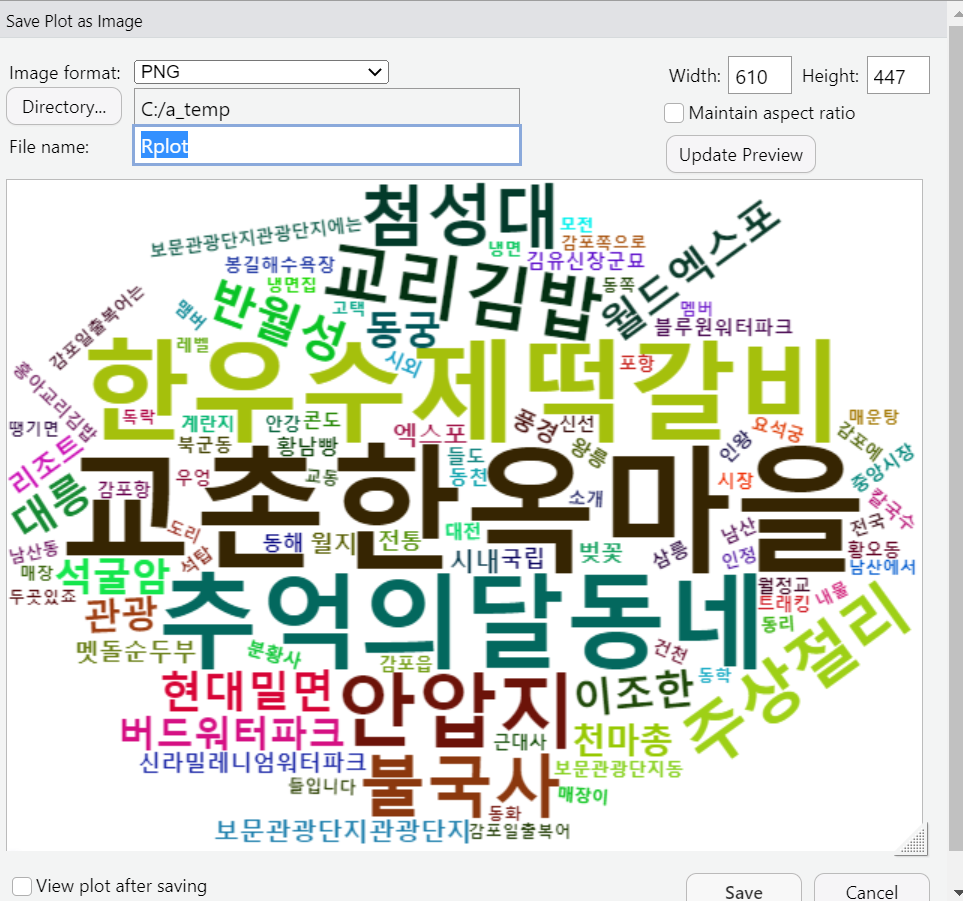

과제 : 미세먼지 분석하기
결과물

'🤔Study . Question🔍' 카테고리의 다른 글
| [Q] Question3. Spring 파트1. About Spring (6) | 2023.07.27 |
|---|---|
| [A] Question3. Spring 파트1. About Spring (0) | 2023.07.27 |
| [A] Question2. 빅데이터분석실무2급 내 맘대로 정리 (정답) (0) | 2023.07.20 |
| [Q] Question1. Git의 모든 것 (문제) (2) | 2023.07.13 |
| [A] Question1. Git의 모든 것 (정답) (0) | 2023.07.13 |



